2 The panorama: what a transformer is and why it won
Where we start. This is the book’s point of departure. Before we open up the engine part by part, it’s worth seeing the whole car: what problem a transformer solves, where it came from, and why —in just a few years— it displaced everything before it and became the foundation of ChatGPT, translators, image models, and almost all of modern AI. No formulas here; just the map. The details come in the chapters that follow.
2.1 The idea in one sentence
A transformer is a neural network that processes a sequence (a text, say) by looking at all its parts at once and learning, at each step, which parts to pay attention to. That ability to attend to what’s relevant, no matter how far away it sits, is what changed everything —and what gives this book its name.
2.2 Key concepts and their role in the transformer
Before we dig in, let’s define this chapter’s terms and what each one is for inside a transformer:
- Sequence. Definition: a series of elements in order (the words of a text, for instance), where the meaning of each depends on the others. In the transformer: it’s the input the model has to understand; the entire design exists to relate parts of a sequence, sometimes very far apart.
- RNN / LSTM. Definition: neural networks that read the sequence word by word, carrying along a “memory” they update at each step. In the transformer: they’re what came before; understanding their two limits —memory that fades and serial processing— explains why something new was needed.
- Attention. Definition: the mechanism that lets a model look at the whole sequence and decide which parts to heed at each step. In the transformer: it’s the central piece —and this book’s— what allows distant words to connect without information getting lost along the way.
- Recurrence. Definition: processing the sequence in order, where each step depends on the result of the previous one. In the transformer: it’s precisely what was removed; without that “step-by-step” dependency, the model can work in parallel.
- Parallelism. Definition: doing many computations at once instead of one after another. In the transformer: by dropping recurrence, it processes all the words at once, which fits GPUs and makes it practical to train on enormous amounts of data.
- Scaling laws. Definition: the observation that these models improve predictably as they grow larger and are given more data. In the transformer: it’s the reason scaling was worth it, and where today’s LLMs came from.
- Block (layer). Definition: the unit repeated many times in the model, with two parts —attention and a feed-forward network. In the transformer: it’s where the essentials happen; stacking blocks is what gives it depth and capacity.
With that in hand, let’s develop them.
2.3 The underlying problem: understanding a sequence
Almost everything interesting in language is a sequence: words come in order and their meaning depends on context. In the sentence “I left the book on the bank”, is it a money bank or a riverbank? Only the rest of the sentence tells you. A machine that wants to understand or generate language therefore needs to relate each word to the others —sometimes to words far away.
For decades, the challenge was exactly that: how do you connect information that is far apart in the sequence? The story of how it was solved is the story that leads to the transformer.
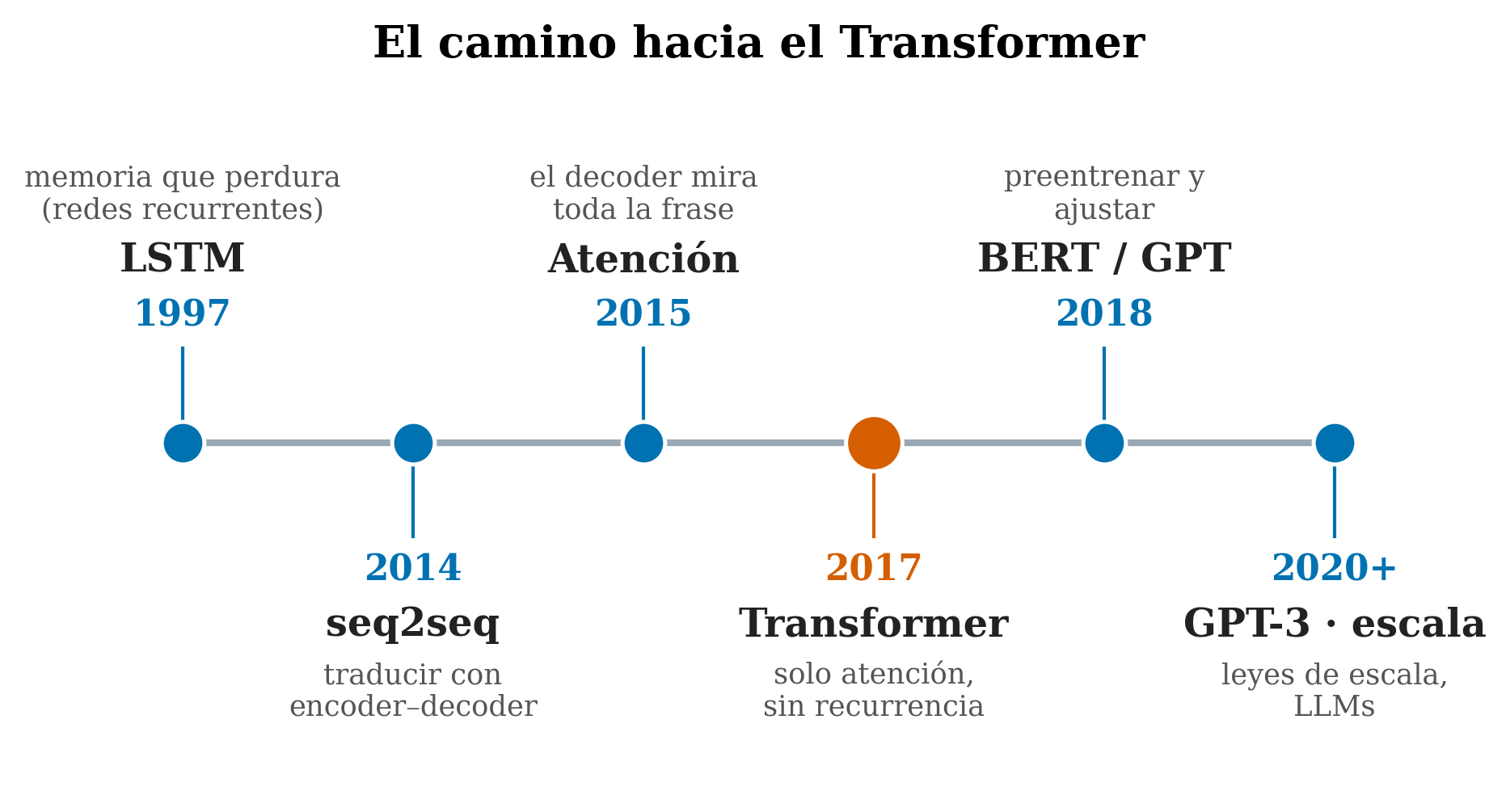
2.4 Before the transformer: reading word by word (RNNs and LSTMs)
The first neural language models were recurrent networks (RNNs, and their improved version, LSTMs (Hochreiter and Schmidhuber 1997)). They worked like a reader who goes word by word carrying along a mental “memory” they update at each step.
🧩 Analogy. Imagine reading a book through a slit that lets you see only one word at a time, trying to remember everything before it in your head. It works for short sentences, but what you read many words ago slowly fades away.
This brought two serious problems:
- Long-range memory dilutes. Connecting the end of a paragraph with its beginning was hard: distant information blurs (the famous vanishing-gradient problem).
- It couldn’t be parallelized. Since each step depends on the previous one, you had to process the sequence in order, one at a time —slow, and unable to exploit GPUs, which shine at doing many things at once.
2.5 The spark: letting the model “look back” (attention)
For translation, the encoder–decoder (seq2seq) scheme (Sutskever et al. 2014) became popular: one network compresses the whole source sentence into a single vector, and another expands it into the target language. But cramming a whole sentence into a single vector is a bottleneck: detail is lost.
The solution, in 2014–2015, was attention (Bahdanau et al. 2015): instead of relying on that single summary, let the decoder, for each word it generates, look at the whole source sentence and decide which words to heed. It was the first time a model explicitly learned where to look. It worked so well that it raised the bold question that would change everything.
2.6 2017: “Attention Is All You Need”
In 2017, a group at Google published a paper with a title that was almost a provocation: “Attention Is All You Need” (Vaswani et al. 2017). Their proposal: remove recurrence entirely and build the model out of attention alone. That model was the Transformer.
2.7 Why it won
Removing recurrence had three enormous consequences:
- Parallelism. Without the “step-by-step” dependency, the transformer processes all the words at once. That fits GPUs perfectly → training on far more data became practical.
- Direct long range. With attention, any word can connect with any other in a single step, without information diluting along the way. The long-memory problem was attacked head-on.
- Scale. It turned out that, as you made them bigger and gave them more data, transformers kept improving predictably (the scaling laws). That set off BERT and GPT (2018), GPT-3 (Brown et al. 2020), and today’s LLMs.
The transformer won not by being “smarter” at small scale, but by parallelizing (exploiting GPUs) and scaling (improving as it grows) better than anything before it. Attention was the mechanism that made both possible.
2.8 What a transformer is, from a bird’s-eye view
Although we’ll devote a chapter to each piece, here’s the blueprint we’ll keep unfolding:
- Tokens — the text is split into pieces and turned into numbers (Chapter 2).
- Embeddings — each token becomes a vector, and its position is added in (Chapter 3).
- A stack of blocks, repeated many times, where the essentials happen. Each block has two parts:
- Attention — each token looks at the others and mixes in their information (the heart of the book).
- Feed-forward network (FFN) — each token processes what it has gathered. …with residual connections and normalization that keep everything stable (Chapters 4–9).
- Output — from the final vectors, the model predicts (e.g., the next word) (Chapter 12).
🧩 Analogy. If an RNN read through a slit, a transformer spreads the whole page out on the table and, for each word, draws lines toward the ones that matter to it. This book is, above all, about how those lines are drawn —and what happens to them when the page gets very, very long.
2.9 Why this book revolves around “attending”
Almost every textbook devotes one chapter to attention and moves on. Here we do the opposite: attention —and in particular how it behaves across distance— is the backbone. It’s where the interesting open questions are (why do models break on very long texts? how do you compress their memory?) and where we contribute our own measurements and tools. But let’s take it in order: first, the foundations.
2.10 Summary
- The challenge of language is to relate parts of a sequence, sometimes very far apart.
- RNNs/LSTMs did it by reading word by word: memory that dilutes, and no parallelism.
- Attention (2014–2015) let the model look at the whole sentence and choose where to focus.
- The Transformer (2017) threw out recurrence and was built from attention alone: parallelizable, with direct long range, and improving as it scales —hence today’s LLMs.
- From a bird’s-eye view: tokens → embeddings → stack of blocks (attention + FFN) → output.
Next (Chapter 2): we begin at the very beginning —how your text is turned into the numbers (tokens) the model can process.
2.11 To think about
- Why was the impossibility of parallelizing RNNs such a big practical problem in the GPU era? (Hint: what does a GPU do well?)
- Attention can connect two distant words “in a single step.” What do you think that will cost when the sequence has thousands of words? (We’ll see in Part II.)