3 De texto a tokens
Dónde estamos. Un modelo de lenguaje no “ve” letras ni palabras: ve números. Este capítulo cubre el primer paso de todo transformer —convertir tu texto en una lista de números enteros llamados tokens— y, sobre todo, el porqué de cada decisión. Al terminar sabrás qué es un token, cómo se trocea el texto, por qué se hace así y no de otra forma, y por qué eso explica rarezas que quizá ya has visto (que contar letras “falle”, que el español gaste más que el inglés, o que pegar código se coma tu contexto).
3.1 La idea en una frase
Antes de pensar, el modelo parte tu texto en trozos pequeños y reutilizables (tokens) y sustituye cada trozo por un número. Toda la inteligencia trabaja luego sobre esos números.
🧩 Analogía. Piensa en las piezas de LEGO. No fabricas una pieza nueva para cada construcción: tienes un catálogo fijo de piezas y combinas las mismas una y otra vez. El “vocabulario” de un modelo es ese catálogo de piezas de texto, y tokenizar es decidir con qué piezas del catálogo se arma tu frase.
Vamos por las preguntas que cualquiera se hace al llegar aquí.
3.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- Token. Definición: un identificador entero para un trozo de texto —normalmente una subpalabra—. En el transformer: es la única forma en que el texto entra al modelo; todo lo demás (embeddings, atención…) opera sobre estos números, no sobre letras.
- Vocabulario. Definición: el diccionario fijo que asigna cada trozo conocido a un número. En el transformer: es el “catálogo de piezas” disponible; su tamaño fija cuántos embeddings hay y cómo de larga sale la secuencia.
- Subpalabra. Definición: un trozo más grande que una letra y más pequeño que una palabra (p. ej.
ción,the). En el transformer: es el punto medio que hace el vocabulario manejable y evita palabras imposibles de representar. - BPE (Byte-Pair Encoding). Definición: el método que arma el vocabulario fusionando iterativamente el par de símbolos más frecuente. En el transformer: es cómo se decide, en la práctica, en qué trozos partir el texto en casi todos los modelos modernos.
- Byte-level BPE. Definición: hacer BPE sobre los 256 bytes del texto en vez de sobre caracteres. En el transformer: garantiza que cualquier texto sea representable, así que nunca aparece un token desconocido (
<UNK>). - WordPiece / Unigram. Definición: las otras dos familias de tokenizadores —una fusiona por verosimilitud (
##), la otra poda un vocabulario enorme de arriba abajo (▁)—. En el transformer: las verás en modelos famosos (BERT, T5, LLaMA-2), y explican marcadores como##o▁. - Tokens especiales. Definición: entradas reservadas del vocabulario que no son texto, sino señales (
<bos>,<eos>,[SEP],[PAD], roles de chat). En el transformer: marcan fronteras y estructura —principio, fin, quién habla— que el modelo necesita para organizar la secuencia. - Tamaño de vocabulario. Definición: cuántos tokens distintos existen. En el transformer: es un compromiso —pequeño da secuencias largas; grande, una matriz de embeddings enorme— que afecta a cómputo, memoria y cuánto texto cabe.
Con esto en mano, los desarrollamos.
3.3 Qué es un token
¿Qué es, exactamente, un “token”? Es un identificador entero para un trozo de texto —normalmente una subpalabra— que es la unidad mínima que el modelo manipula. El modelo guarda un diccionario (el vocabulario) que asigna cada trozo conocido a un número:
"Hola" → 15496
" mundo" → 1917
"!" → 0Tu frase se convierte en la lista [15496, 1917, 0]. Eso es todo lo que entra al modelo. Cada número tendrá luego asociado un vector aprendido (el embedding, en el capítulo siguiente), pero el token en sí es solo el número.
3.4 Por qué no usar palabras enteras
Es lo primero que uno piensa —¿por qué no un token por palabra?— y no funciona bien, por dos motivos:
- El vocabulario explota. Hay millones de palabras (más flexiones, nombres propios, erratas, idiomas…). Una entrada por palabra significaría una tabla gigantesca.
- Las palabras nuevas rompen el sistema. Si “antidisturbios” no estaba en el catálogo, no hay número para ella: queda como “desconocida” (
<UNK>) y el modelo pierde información. Y siempre aparecen palabras nuevas.
3.5 Por qué tampoco letra a letra
¿Y por qué no ir carácter a carácter? Así nunca te quedas sin piezas… pero el problema es el opuesto: las secuencias se hacen larguísimas. “antidisturbios” serían 14 tokens en vez de 1 o 2. Como veremos, el coste de la atención crece con el cuadrado de la longitud, así que ir letra a letra dispara el cómputo y desperdicia contexto.
La solución intermedia: subpalabras. Trozos más grandes que una letra y más pequeños que una palabra. Las piezas frecuentes (“de”, “ción”, ” the”) son un solo token; las raras se arman juntando piezas. Así el catálogo es manejable y nunca hay palabra imposible de representar. Casi todos los modelos modernos usan subpalabras.
3.6 Cómo se decide el troceo: BPE
¿Cómo se decide en qué trozos partir? El método más extendido es Byte-Pair Encoding (BPE) (Sennrich et al. 2016). La idea es sorprendentemente simple y se aprende mejor con un ejemplo. Partimos de un mini-corpus donde solo aparecen cuatro palabras, con sus frecuencias, y empezamos con el texto separado en caracteres:
low ×5 → l o w
lower ×2 → l o w e r
newest×6 → n e w e s t
widest×3 → w i d e s tRegla de BPE: cuenta todos los pares de símbolos adyacentes y fusiona el par más frecuente en un símbolo nuevo. Repite N veces.
- Paso 1: el par
e saparece ennewest(6) ywidest(3) → 9 veces, el más frecuente. Se fusiona:es. Ahoranewest=n e w es t. - Paso 2: ahora
es taparece 9 veces → se fusiona enest. - Paso 3:
l oaparece enlow(5) ylower(2) → 7 veces → se fusiona enlo.
Tras unas fusiones, “lowest” (que nunca vimos) se tokeniza sin problema como lo + w + est: piezas que sí aprendimos. El tamaño del vocabulario es simplemente caracteres base + número de fusiones, y ese número de fusiones es un botón que tú eliges.
BPE es puramente dirigido por frecuencia y determinista: siempre fusiona el par más común. No hay magia lingüística; las piezas que salen son estadísticas, no necesariamente morfemas (volveremos a esto).
3.7 BPE a nivel de bytes
¿Qué es eso de “a nivel de bytes” que aparece en GPT? Un BPE normal trabaja sobre caracteres Unicode, y aun así puede toparse con un carácter rarísimo que nunca vio (un emoji, un ideograma poco común). GPT-2 (Radford et al. 2019) lo resolvió con un truco: hacer BPE sobre los bytes del texto (su codificación UTF-8) en vez de sobre caracteres.
Por qué importa. Solo hay 256 bytes posibles, así que con esos 256 símbolos base cualquier texto del mundo —cualquier idioma, emoji, símbolo o código— es representable. Resultado: nunca aparece un token “desconocido”. Por eso GPT-2, LLaMA-3, Qwen… usan byte-level BPE. (El vocabulario de GPT-2 son 50.257 tokens: 256 bytes + 50.000 fusiones + 1 token de fin de texto.)
3.8 Otras familias: WordPiece y Unigram
¿Hay otras formas además de BPE? Sí, dos que conviene conocer porque las verás en modelos famosos:
- WordPiece (Schuster y Nakajima 2012) (lo usa BERT). Fusiona pares como BPE, pero en vez de elegir el más frecuente elige el que más aumenta la verosimilitud del corpus —en la práctica, el par con mejor
frec(par) / (frec(a)·frec(b))—donde a y b son las dos piezas del par—. Premia fusionar piezas que casi solo aparecen juntas (no las ya comunes por separado), y así evita pegar a lo bruto piezas ya comunes. Marca las piezas que continúan una palabra con##: “palabra” →palab ##ra. - Unigram / SentencePiece (Kudo 2018; Kudo y Richardson 2018). Va al revés: arranca con un vocabulario enorme de candidatos y va podando los tokens que menos se echan de menos, hasta el tamaño deseado. SentencePiece, además, trata el texto como un flujo en bruto incluyendo los espacios (los marca con
▁), lo que hace la tokenización perfectamente reversible y agnóstica del idioma. Lo usan T5, LLaMA-2 o Gemma.
BPE y WordPiece fusionan de abajo arriba; lo único que cambia es el criterio (frecuencia bruta vs. verosimilitud). Solo Unigram va de arriba abajo (podando). Y “SentencePiece” no es un algoritmo, es una biblioteca que por dentro corre BPE o Unigram. Los marcadores ## (WordPiece) y ▁/Ġ (SentencePiece/GPT-2) resuelven el mismo problema —saber si una pieza empieza palabra nueva— de formas opuestas.
3.9 El proceso completo, de principio a fin
¿Cómo encaja todo, de tu texto a la lista de números? En las librerías modernas (p.ej. HuggingFace tokenizers) la tokenización son cuatro etapas en cadena:
- Normalización — limpieza Unicode (NFC/NFKC), a veces minúsculas o quitar acentos.
- Pre-tokenización — un primer corte burdo (por espacios y puntuación) para no fusionar a través de fronteras raras.
- Modelo — aquí actúa BPE / WordPiece / Unigram para trocear en subpalabras.
- Post-proceso — añade tokens especiales (
[CLS],[SEP],<eos>…) y metadatos.
3.10 Tokens especiales
¿Y los tokens que no son texto? Son señales para el modelo: principio de secuencia (<bos>), fin (<eos> / <|endoftext|>), separador ([SEP]), relleno ([PAD]), o marcadores de rol en un chat (<|user|>, <|assistant|>). Ocupan entradas reservadas del vocabulario.
3.11 El tamaño del vocabulario
¿Cuántos tokens conviene tener: vocabulario grande o pequeño? Es un compromiso, no hay un “mejor”:
- Vocabulario pequeño → lista de tokens corta, pero secuencias más largas (más cómputo, menos texto cabe en el contexto).
- Vocabulario grande → secuencias más cortas, pero una matriz de embeddings enorme (más parámetros y memoria) y muchos tokens que apenas se entrenan.
Los modelos reales han ido creciendo, sobre todo para cubrir bien varios idiomas:
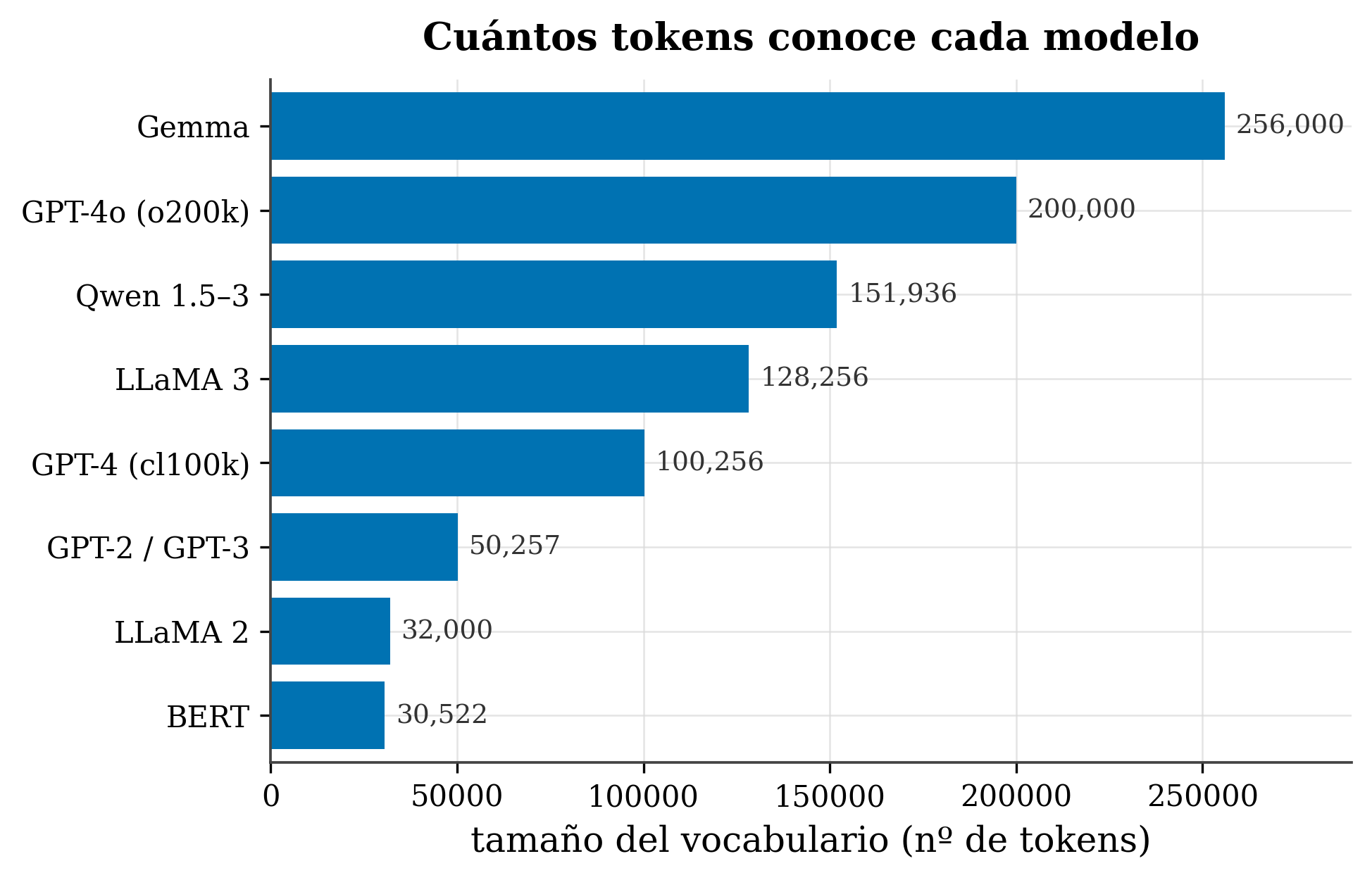
figures/make_fig02_vocab.py.
| Modelo | Tokenizador | Vocabulario |
|---|---|---|
| BERT | WordPiece | 30.522 |
| LLaMA 2 | SentencePiece-BPE | 32.000 |
| GPT-2 / GPT-3 | byte-level BPE | 50.257 |
| GPT-4 (cl100k) | byte-level BPE | ~100.256 |
| LLaMA 3 | byte-level BPE | 128.256 |
| Qwen 1.5–3 | byte-level BPE | 151.936 |
| GPT-4o (o200k) | byte-level BPE | ~200.000 |
| Gemma | SentencePiece | 256.000 |
3.12 Cuánto texto cabe en un token
Como regla aproximada, en inglés un token equivale a ~4 caracteres (unas 0,75 palabras). Pero ojo:
Eso es solo el promedio en inglés del BPE a nivel de bytes; no es una regla. En español, alemán o —peor— en idiomas no latinos, el mismo contenido gasta 2 a 4 veces más tokens (los tokenizadores se entrenan sobre todo con inglés). Y en código, la indentación y los espacios desperdician tokens salvo que el tokenizador tenga piezas para secuencias de espacios. Por eso una traducción “igual de larga” puede costarte mucho más contexto.
3.13 Qué “significan” los tokens
¿Tiene cada token un significado? Cada token recibirá un vector aprendido, y tokens relacionados acaban cerca en ese espacio —así que en cierto sentido el modelo les da significado—. Pero la frontera de un token es estadística, no lingüística: no tiene por qué coincidir con un morfema. “tokenization” se parte en token + ization, pero otras palabras se parten de formas que a un lingüista le chirrían. El token es una pieza de compresión, no una unidad de sentido.
3.14 Rarezas que ahora entenderás
- El espacio inicial cuenta.
" the"(con espacio) y"the"(sin él) son tokens distintos, con números distintos. Por eso la misma palabra a principio de frase o en medio puede tokenizarse diferente. - Los números se parten raro.
"12345"puede salir como["123","45"]; GPT-2 no trataba los dígitos de forma especial, de ahí parte de su fama de malo con la aritmética. - Glitch tokens.
" SolidGoldMagikarp"(un usuario de Reddit) llegó a ser un único token en GPT-2, visto tan pocas veces en entrenamiento que provocaba comportamientos erráticos. Los tokenizadores nuevos lo parten en trozos normales.
3.15 Pruébalo
# pip install tiktoken
import tiktoken
enc = tiktoken.get_encoding("cl100k_base") # el de GPT-3.5/4
print(enc.encode("tokenization")) # -> [token, ization] (2 tokens)
print(enc.encode(" the") == enc.encode("the")) # -> False (¡el espacio importa!)
for t in enc.encode("Hola mundo!"):
print(t, repr(enc.decode([t]))) # ver cada token y su textoPega cualquier frase (en español, en inglés, o código) en un visor de tokenización como tiktokenizer y mira en tiempo real cómo se trocea y cuántos tokens cuesta. Verás de un vistazo la penalización del español y del código frente al inglés.
3.16 Resumen
- Un token es un número entero que representa un trozo de texto (normalmente una subpalabra); es lo único que entra al modelo.
- Ni palabras (vocabulario infinito, palabras desconocidas) ni caracteres (secuencias larguísimas): subpalabras es el punto medio.
- BPE fusiona iterativamente el par más frecuente; byte-level BPE trabaja sobre los 256 bytes y por eso nunca tiene tokens desconocidos.
- WordPiece (criterio de verosimilitud,
##) y Unigram/SentencePiece (podado top-down,▁) son las otras dos familias. - El tamaño de vocabulario es un compromiso (secuencia corta vs. matriz grande); los modelos reales van de 30k a 256k.
- “4 caracteres por token” es solo el promedio en inglés; otros idiomas y el código cuestan más. Las fronteras de token son estadísticas, no lingüísticas.
Siguiente (Capítulo 3): ya tenemos números. El siguiente paso es darle a cada token un vector —su embedding— y colocarlo en el flujo residual, la “memoria” por la que viaja la información dentro del modelo.
3.17 Ejercicios
- A mano. Con el mini-corpus de arriba (
low×5,lower×2,newest×6,widest×3), haz las dos siguientes fusiones de BPE después dees,est,lo. ¿Qué par toca ahora? - El espacio. En código, tokeniza
"the"," the"y" the"(con dos espacios) contiktokeny compara las listas. Explica por qué difieren. - El impuesto multilingüe. Tokeniza la misma frase en inglés y en español (p.ej. “the house is big” vs “la casa es grande”) y cuenta los tokens de cada una. ¿Cuál gasta más? Relaciónalo con el coste de contexto.
- Sin desconocidos. Explica con tus palabras por qué un tokenizador a nivel de bytes nunca necesita un token
<UNK>, mientras que uno a nivel de palabra sí.