16 La ley de decaimiento A(d) ∝ d^−γ
Dónde estamos. En el Cap. 14 vimos por qué la geometría de RoPE limita la resolución con la distancia. Ahora llegamos al corazón de nuestro trabajo: la ley que resume ese decaimiento, por qué es una ley de potencia (no otra cosa), y —lo más importante y único— cómo predecir su exponente γ desde la geometría del modelo, sin entrenar ni ajustar nada. Lo explico paso a paso; no hace falta saber estadística para seguirlo.
16.1 La idea en una frase
La atención media entre dos tokens cae como una ley de potencia con la distancia, A(d) ∝ d^−γ, y el exponente γ se puede predecir desde la geometría de RoPE.
16.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- Ley de potencia A(d) ∝ d^−γ. Definición: la atención media a distancia d cae como una potencia de d. En el transformer: resume en una sola forma cómo reparte el modelo su atención a lo largo de la distancia; en ejes log-log es una recta.
- γ (exponente de decaimiento). Definición: la pendiente (con signo menos) de esa recta log-log; cuánto de rápido cae la atención. En el transformer: es el descriptor central — dice si el modelo mira lejos o concentra cerca.
- Restricción log-distancia. Definición: lo único que la geometría de RoPE fija en promedio es \(\mathbb{E}[\log d] = \text{constante}\) (un “presupuesto” de log-distancia). En el transformer: es el dato de partida del que se deriva la forma de la atención.
- Máxima entropía. Definición: el principio de elegir la distribución que asume lo mínimo compatible con lo que sabes. En el transformer: aplicado a la restricción log-distancia, da de forma única la ley de potencia (γ es su multiplicador de Lagrange) — la power-law es una derivación, no un ajuste.
- γ_Padé. Definición: la predicción de γ desde solo θ y T, \(\gamma_{\text{Padé}} = (2\theta - T\sqrt2)/(2\theta + T\sqrt2)\), sin entrenar ni ajustar nada. En el transformer: es nuestro diferencial — predecir el centro de γ a partir de la geometría, no solo observarlo.
- Descomposición de γ. Definición: \(\gamma_{\text{obs}} = \gamma_{\text{geom}} + \gamma_{\text{train}} + \gamma_{\text{arch}} + \varepsilon\). En el transformer: explica de dónde viene cada parte de γ y por qué la predicción geométrica acierta el centro pero no el valor exacto.
- Regímenes (Fase A / Hagedorn / Fase B). Definición: γ<1 (mira lejos), γ=1 (frontera de Hagedorn), γ>1 (concentra cerca). En el transformer: clasifica cómo usa el contexto el modelo, con consecuencias prácticas en los próximos capítulos.
En resumen: la forma (power-law) se deriva, el exponente (γ) se predice de forma aproximada, y la descomposición explica lo que la geometría sola no captura.
16.3 La ley, y qué es γ
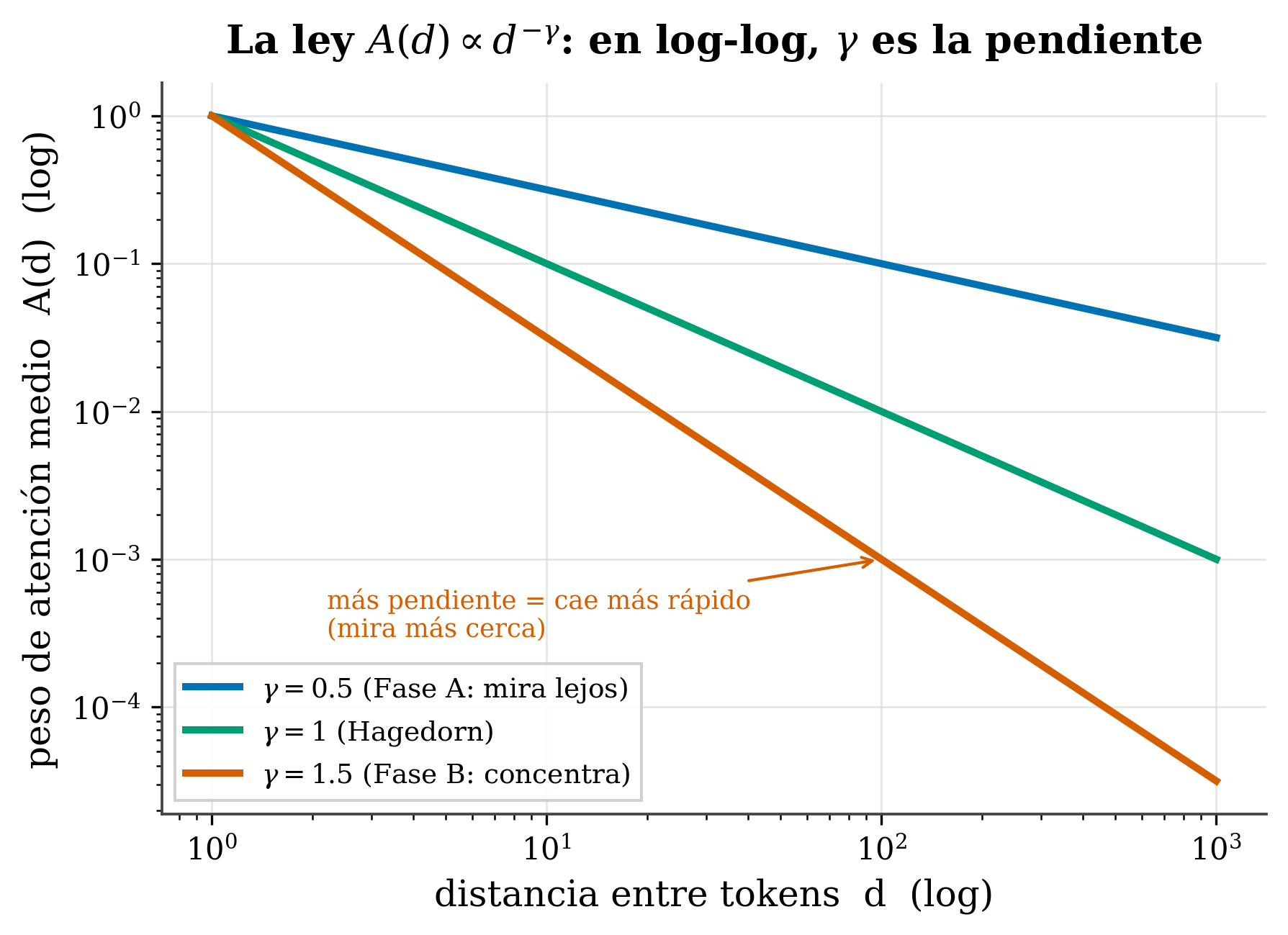
A(d)∝d^−γ en ejes log-log: aparece como una recta cuya pendiente es −γ. γ pequeño (Fase A) = cae despacio, el modelo mira lejos; γ grande (Fase B) = cae rápido, concentra cerca; γ=1 es la frontera (Hagedorn).
- A(d) = peso de atención medio a distancia d.
- γ (gamma) = el exponente de decaimiento: cuánto de rápido cae la atención.
Un truco para verlo: en ejes log-log, una ley de potencia es una línea recta, y γ es su pendiente (con signo menos). Medir γ es, literalmente, medir esa pendiente.
16.4 ¿Por qué una ley de POTENCIA, y no otra forma?
Esta es la parte bonita —y es nuestra—. La respuesta sale de dos ideas encadenadas.
Paso 1 — RoPE impone una restricción “log-distancia”. Por su estructura de frecuencias logarítmica (Cap. 14), lo único que la geometría de RoPE “fija”, en promedio, es el logaritmo de la distancia típica a la que se atiende: \(\mathbb{E}[\log d] = \text{constante}\) (donde E[·] significa promedio o valor esperado). En cristiano: el modelo tiene un “presupuesto” fijo de log-distancia, no de distancia.
Paso 2 — máxima entropía. Entre todas las formas de repartir la atención compatibles con esa única restricción, ¿cuál elegir?
🧩 Analogía. Si lo único que te dicen de un dado es que su media sale 3,5, la apuesta más honesta es que el dado es justo (uniforme): no inventas sesgos que nadie te ha dado. Eso es la máxima entropía: la distribución que asume lo mínimo compatible con lo que sabes. (Es el mismo principio que en física da la distribución de Boltzmann.)
Y aquí está el resultado matemático clave: la distribución de máxima entropía compatible con “E[log d] fijo” es, de forma única, una ley de potencia \(p^*(d) \propto d^{-\gamma}\). Ni exponencial, ni gaussiana, ni con corte: solo la power-law cumple las dos cosas a la vez. El exponente γ es el “multiplicador de Lagrange” de esa restricción —en cristiano, la perilla que la restricción fija, no algo que pongamos a mano—.
La ley de potencia no es un ajuste a los datos: es la única respuesta a una pregunta de inferencia bien planteada (máxima entropía + restricción log-distancia de RoPE). RoPE no solo codifica posición: restringe el flujo de información, y esa restricción determina la forma de la distribución de atención.
16.5 Lo verdaderamente único: PREDECIR γ desde la geometría
Que la atención decae como power-law es algo que también observan otros (p. ej. Attention’s Gravitational Field (Zhang 2026), lo ajusta por cabeza). Nuestro diferencial no es ver el decaimiento, sino predecir su exponente —sin ajustar nada— a partir de solo dos números: la base θ de RoPE y la longitud T:
\[ \gamma_{\text{Padé}} = \frac{2\theta - T\sqrt2}{\,2\theta + T\sqrt2\,} \]
Qué hace cada término:
- θ = la base de RoPE (un hiperparámetro del modelo, p. ej. 10000). Al subir θ, el numerador y el denominador se parecen cada vez más → γ → 1 (el modelo mira lejos).
- T = la longitud de contexto que evalúas. Al subir T, el término
T√2pesa más → γ baja (la atención cae más rápido). - √2 = una constante que sale de la geometría de RoPE.
- El conjunto numerador/denominador es una transformada de Cayley: comprime la pugna entre θ (mirar lejos) y T√2 (contexto largo) en un γ acotado.
Esto da el valor central de γ antes de entrenar nada.
Tres salvedades que hacemos explícitas (y que nos distinguen de vender humo): 1. La predicción es aproximada. En nuestra propia revisión honesta, el error de predicción de γ_Padé tiene una mediana de ~20–22% en Fase A (corregimos un 4,3% previo que era demasiado optimista). γ_Padé acierta el centro, no el valor exacto. 2. No afirmamos que RoPE imponga el decaimiento. Como vimos en el Cap. 14 (Round and Round (Barbero et al. 2024), HoPE (Chen et al. 2024)), la geometría acota la resolución alcanzable; γ describe lo que hacen los modelos entrenados, no es un decreto. 3. La ley es robusta como descripción: A(d)∝d^−γ ajusta con R² > 0,95 en 46 medidas sobre 30+ modelos (de Pythia-70M a BLOOM-7B). Lo sólido es la forma; lo aproximado es predecir el exponente exacto.
16.6 Por qué la predicción no es perfecta: la descomposición
γ medido no es solo geometría. Lo descomponemos para saber de dónde viene cada parte:
\[ \gamma_{\text{obs}} = \underbrace{\gamma_{\text{geom}}(\theta, T)}_{\text{lo que predecimos}} + \gamma_{\text{train}} + \gamma_{\text{arch}} + \varepsilon \]
- γ_geom = lo que fija la geometría (= γ_Padé). Lo que entendemos analíticamente.
- γ_train = lo que añaden los datos de entrenamiento (la formación de induction heads; aparece a partir de ~400M parámetros).
- γ_arch = lo que añade la arquitectura (GQA, ventana deslizante).
- ε = residuo.
Ese ~20% de error de la predicción no es ruido inexplicado: es, en buena parte, γ_train + γ_arch. Por eso γ_Padé predice el centro y la descomposición explica el resto. (Honesto: el término γ_train/imprint —cuya pendiente ν≈−1/2π mediría cuánto “imprimen” los datos de entrenamiento su huella en γ— es provisional —lo veremos con esa salvedad—.)
16.7 Los regímenes: γ<1, γ=1, γ>1
El valor de γ dice cómo usa el contexto el modelo (lo desarrollamos en los próximos capítulos):
- γ < 1 (Fase A): cola pesada, mira lejos → aprovecha contexto amplio.
- γ = 1 (Hagedorn): la frontera entre ambos.
- γ > 1 (Fase B): concentra cerca (mucha masa en poco contexto).
En tafagent, modo Profile, pega un model id: te calcula γ_Padé (predicho desde θ y T), lo compara con γ_observado, y te dice en qué régimen (Fase A/B) cae tu modelo y su horizonte efectivo. Es, literalmente, esta teoría hecha herramienta.
16.8 Resumen
- La atención decae como ley de potencia
A(d)∝d^−γ; en log-log, γ = pendiente. - Por qué power-law: es la única distribución de máxima entropía compatible con la restricción log-distancia de RoPE; γ = multiplicador de Lagrange. No es un ajuste, es una derivación.
- Lo único nuestro: predecir γ desde la geometría (γ_Padé, cero parámetros) —no solo observarlo—.
- Honesto: la predicción es aproximada (mediana ~20% error en Fase A, revisión propia; no el 4,3% previo); la forma power-law sí es sólida (R²>0,95, 30+ modelos); γ es un descriptor medido, no un decreto geométrico.
- Descomposición γ_obs = γ_geom + γ_train + γ_arch + ε explica por qué la predicción no es exacta.
- Regímenes: γ<1 mira lejos · γ=1 Hagedorn · γ>1 concentra.
Siguiente (Capítulo 16): si podemos medir γ en cualquier modelo, midámoslo en muchos — el atlas γ de 42 modelos, el mapa cross-arquitectura que nadie más tiene.
16.9 Ejercicios
- La pendiente. En unos ejes log-log ves dos rectas de atención, una con pendiente −0,4 y otra con −1,3. ¿Cuál mira más lejos? ¿Cuál es Fase A y cuál Fase B?
- Máxima entropía. Con tus palabras: ¿por qué “la distribución más honesta dado solo E[log d]” es la power-law y no una gaussiana?
- Predicción honesta. Si γ_Padé predice 0,7 y el γ medido es 0,55, ¿qué término de la descomposición podría explicar la diferencia?
- Herramienta. ¿Qué tres cosas te devuelve tafagent al perfilar un modelo respecto a γ?
La derivación completa de γ_Padé, la descomposición de seis ejes y los datos que sustentan este capítulo están en abierto: Predicting How Transformers Attend (Zenodo).