25 Dinámica de entrenamiento y grokking
Dónde estamos. Cerramos la Parte III con el fenómeno más desconcertante del entrenamiento: un modelo que memoriza rápido, se queda atascado sin generalizar durante muchísimo tiempo… y de pronto, mucho después, generaliza de golpe. Es el grokking. Lo explicamos de cero, contamos lo que la ciencia ha descubierto sobre por qué ocurre, y presentamos —con su alcance honesto— un resultado piloto nuestro: una señal interna y barata que se enciende antes del salto.
25.1 La idea en una frase
A veces la comprensión de una red no llega cuando deja de equivocarse en el entrenamiento, sino mucho después: el circuito que de verdad generaliza se va formando en silencio bajo la superficie, y el “salto” que vemos es solo el momento en que por fin pesa más que la memorización.
25.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- Grokking. Definición: el patrón en que una red memoriza rápido (train→100 %, test al azar), pasa una meseta larga y luego generaliza de golpe. En el transformer: el fenómeno de entrenamiento que estudia todo el capítulo, visible como dos sigmoides muy separadas.
- Memorización vs. generalización. Definición: almacenar las respuestas vistas sin estructura útil, frente a aprender el patrón que resuelve casos nuevos. En el transformer: las dos soluciones que compiten durante el entrenamiento; el “salto” es cuando la segunda por fin gana.
- Algoritmo de Fourier. Definición: el mecanismo que Nanda halló en la suma modular —colocar números como ángulos y convertir “sumar” en “girar”—. En el transformer: el circuito que de verdad generaliza, y que se forma gradualmente bajo la meseta.
- Medida de progreso. Definición: una cantidad continua medible a cada paso (p. ej. cuánta representación se concentra en pocas frecuencias). En el transformer: permite ver que el circuito generalizador crece antes del salto visible.
- Mecanismo LU y weight decay. Definición: la pérdida de train tiene forma de “L” (muchas soluciones memorizan) y la de test forma de “U” (solo generaliza una franja de norma pequeña); el weight decay penaliza pesos grandes y arrastra hacia ahí. En el transformer: el motor que empuja de la solución memorizadora a la generalizadora; sin él, muchos modelos nunca grokean.
- Parámetro de orden. Definición: el “termómetro” que delata una transición de fase —una cantidad que cambia cualitativamente al cruzar el umbral—. En el transformer: el marco con que la frontera (2024-2026) lee el grokking como transición de fase.
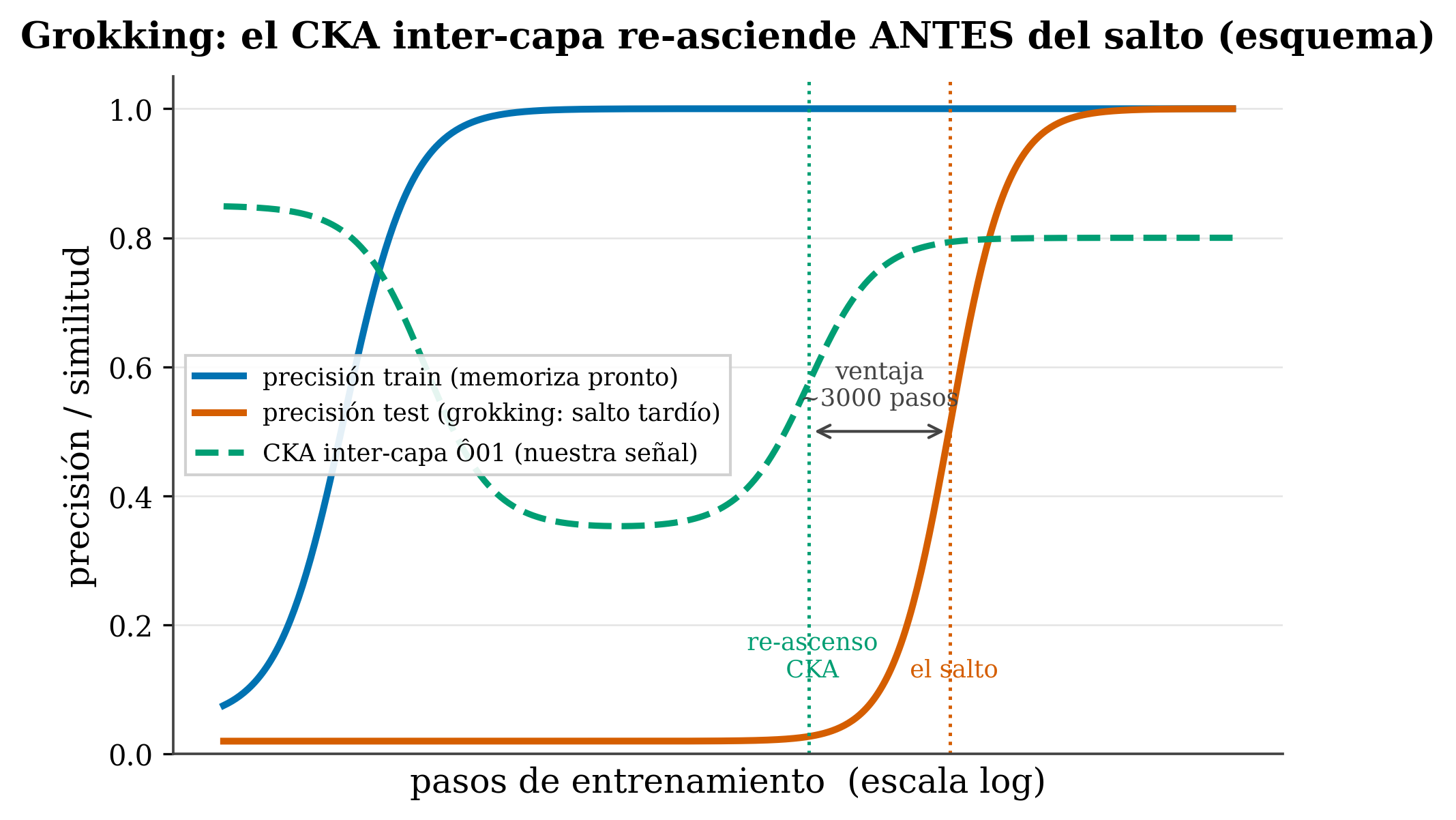
- CKA inter-capa \(\hat{O}_{01}\). Definición: Centered Kernel Alignment, un número en [0,1] que mide cuánto se parecen las representaciones de la capa 0 y la capa 1. En el transformer: nuestra señal piloto —cae durante la memorización y re-asciende antes del salto—.
- Predictivo vs. causal. Definición: una señal que anticipa un evento frente a una palanca que lo provoca. En el transformer: el re-ascenso del CKA resultó ser predictivo, no causal —forzarlo no fabrica grokking—.
La idea de fondo: el grokking no es mágico por dentro; algo medible se forma despacio, y saber leerlo permite anticipar el salto (aunque no accionarlo).
25.3 Qué es el grokking
El término lo acuñaron Power y colaboradores en 2022 (Power et al. 2022) estudiando tareas algorítmicas pequeñas —el ejemplo canónico es la suma o multiplicación módulo un primo \(p\) (aritmética sobre un reloj de \(p\) horas)—. Entrenaron un transformer pequeño y observaron una curva que rompe la intuición clásica:
- Fase de memorización (pronto). En pocos pasos, la precisión en el conjunto de entrenamiento sube a ~100 %. El modelo se ha aprendido las respuestas de memoria. La precisión en test (ejemplos no vistos) sigue en el azar.
- Meseta larga. Durante un periodo larguísimo —a menudo mil veces más pasos que los que costó memorizar— nada parece cambiar: train clavado en 100 %, test en el suelo. Por la lógica clásica del sobreajuste, aquí deberíamos parar: el modelo “ya ha terminado” y solo está memorizando.
- El salto (grok). Y entonces, sin previo aviso, la precisión en test se dispara hasta casi el 100 %. El modelo generaliza —“hace clic”— mucho después de haber dejado de mejorar en entrenamiento. De ahí el nombre: to grok es entender algo de forma profunda y repentina.
La firma visual son dos sigmoides muy separadas sobre un eje de pasos en escala logarítmica: la de train sube pronto, la de test sube tardísimo (Figura 25.1, curvas azul y naranja). Power también notó que cuanto más pequeño es el conjunto de datos, desproporcionadamente más optimización hace falta para que llegue el salto.
🧩 Analogía — el estudiante que empolla. Un alumno memoriza las tablas de multiplicar a base de repetir. Durante semanas recita de carrerilla las que ha visto (alta precisión “de entrenamiento”), pero falla en cuanto le pones un problema nuevo (test al azar). Un día el patrón subyacente encaja y de pronto resuelve cualquier caso, lo haya visto o no. Lo interesante: la comprensión se estaba montando en silencio todo ese tiempo; el “¡ajá!” es solo el instante en que por fin supera a la costumbre de recitar.
25.4 Por debajo no es tan súbito: el algoritmo que se forma despacio
El salto parece mágico, pero Nanda y colaboradores (Nanda et al. 2023) lo desmontaron pieza a pieza con interpretabilidad mecanicista (abrir la red y leer qué calcula de verdad). En la suma modular, descubrieron que el modelo aprende un algoritmo de Fourier concreto: coloca cada número como un ángulo sobre un círculo y convierte “sumar” en “girar”, usando identidades trigonométricas. Sumar \(a+b \bmod p\) se vuelve componer dos rotaciones.
Lo decisivo para entender el grokking es cómo aparece ese algoritmo. Nanda definió medidas de progreso —cantidades continuas que se pueden mirar a cada paso, como cuánta de la representación está concentrada en unas pocas frecuencias de Fourier— y vio que el circuito generalizador se va formando de forma gradual, mucho antes del salto visible. El entrenamiento se parte en tres etapas:
- Memorización: la red almacena las respuestas vistas sin estructura útil.
- Formación del circuito: en paralelo, y lentamente, se construye el mecanismo de Fourier que sí generaliza.
- Limpieza (cleanup): una vez el circuito bueno funciona, los componentes de pura memorización se eliminan.
La moraleja, importante y contraintuitiva: el grokking no es realmente súbito por dentro. La estructura que generaliza se amplifica poco a poco; la brusquedad que vemos en la curva de test es un artefacto del momento en que ese circuito —que llevaba rato cocinándose— por fin domina y la memorización se retira. Por eso tiene sentido buscar señales tempranas: si algo se está formando gradualmente bajo la superficie, debería poder medirse antes de que aflore.
25.5 Por qué ocurre: el paisaje de pérdida y el weight decay
¿Qué empuja a la red de la región memorizadora a la generalizadora? La respuesta más nítida la dieron Liu, Michaud y Tegmark en Omnigrok (Liu et al. 2022), mirando el paisaje de pérdida en función de la norma de los pesos (cómo de “grandes” son los parámetros en conjunto):
- La pérdida de entrenamiento, vista frente a la norma, tiene forma de “L”: cae pronto y se queda baja en un rango amplio de normas (hay muchas soluciones que memorizan bien).
- La pérdida de test tiene forma de “U”: solo es baja en una franja estrecha de norma pequeña —ahí vive la solución que de verdad generaliza—.
A esto lo llaman el mecanismo LU. La clave práctica es el weight decay (la regularización que penaliza pesos grandes; lo vimos en el Cap. 11): empuja la norma hacia abajo lentamente, arrastrando los pesos desde la zona memorizadora (norma alta) hacia el mínimo generalizador (norma baja). El grokking aparece justo cuando ese arrastre completa el viaje. Encaja con la “limpieza” de Nanda: la regularización retira la solución de norma alta una vez existe un circuito general de norma baja. Sin weight decay suficiente, muchos modelos nunca llegan a generalizar —se quedan en la meseta para siempre—.
25.6 Cómo lo está mirando la frontera (2024-2026): cada cual con su “termómetro”
El grokking se ha vuelto un laboratorio de transiciones de fase en redes (conecta directamente con nuestra Parte III: un cambio cualitativo brusco gobernado por un parámetro de orden, el “termómetro” que delata la transición). Tres trabajos recientes proponen parámetros de orden distintos:
- Colapso de entropía espectral (Khanh et al. 2026): el parámetro de orden es la entropía espectral de la matriz de covarianza de las representaciones —cómo de “repartida” está la información entre direcciones—. Colapsa al cruzar un umbral antes de que suba el test; los autores lo plantean explícitamente como marco predictivo y lo ligan a representaciones alineadas con Fourier.
- Transición dimensional (Wang 2026): el parámetro es la dimensionalidad efectiva de la dinámica de gradientes, que cruza de un régimen sub-difusivo a uno super-difusivo en el inicio de la generalización (criticalidad autoorganizada).
- Defecto de conmutador (Xu 2026): mide la curvatura que provoca que las actualizaciones de gradiente no conmuten entre sí; esa señal sube antes del salto, y forzar esa no-conmutatividad acelera el grokking.
25.7 Nuestro resultado piloto: el re-ascenso del CKA inter-capa
Aquí está nuestra aportación, y la presentamos con su alcance exacto —es un estudio piloto, no una ley cerrada—.
Medimos, paso a paso durante el entrenamiento, el CKA inter-capa: la similitud representacional entre lo que calcula la capa 0 y lo que calcula la capa 1.
CKA (Centered Kernel Alignment) es un número entre 0 y 1 que responde a “¿cuánto se parecen dos conjuntos de representaciones?”. 1 = prácticamente la misma estructura; 0 = nada que ver. Lo aplicamos entre dos capas del mismo modelo (capa 0 vs capa 1), de ahí “inter-capa”. Lo llamamos \(\hat{O}_{01}\).
El patrón que observamos en los modelos que sí acaban grokking:
- \(\hat{O}_{01}\) empieza alto (al inicio, las capas hacen cosas parecidas).
- Cae durante la memorización (las capas se especializan en memorizar, cada una a lo suyo).
- Y entonces re-asciende —vuelve a subir— unos ~3000 pasos antes de que la precisión de test dé el salto (Figura 25.1, curva verde).
figures/make_fig24_grokking.py.
Esa re-subida temprana es la señal: cuando \(\hat{O}_{01}\) vuelve a crecer, el salto de generalización está por llegar. En nuestro piloto, la señal aparece en 16 de 16 modelos que grokean y en 0 de 5 que no, y replica en suma modular con varios primos y en multiplicación modular. La tarea de paridad \(k\)-dispersa marca el borde del fenómeno: ahí la coordinación entre capas funciona distinto y la señal se difumina, lo que acota su alcance a tareas de tipo Fourier donde la generalización exige que las capas se coordinen.
Tiene sentido con la historia de Nanda: si el circuito generalizador se monta gradualmente y necesita que dos capas trabajen juntas, su similitud representacional debería recuperarse mientras se ensambla —antes de que el resultado aflore en el test—.
Dos cautelas que no nos saltamos:
- “Predecir el grokking” NO es una idea nueva nuestra. Ya hay trabajo dedicado a ello —uno se titula literalmente Early-Warning Signals of Grokking (Xu 2026), y el de entropía espectral (Khanh et al. 2026) también predice el tiempo hasta el salto—. Nuestra contribución no es “ser los primeros en predecir”, sino una señal concreta, simple e interna al entrenamiento (el CKA inter-capa) que es barata de medir, es entre capas (no covarianza dentro de una) y da una ventaja temporal medible.
- Es un piloto, no una ley. Un solo estudio es evidencia más débil que los trabajos multi-semilla de la literatura. Aún debemos validar la ventaja temporal y la robustez entre semillas con el mismo rigor que ellos. Y el CKA es un proxy lineal de la similitud: útil, pero no la última palabra. El vecino más cercano a citar es el colapso de entropía espectral, que también toca la geometría de las representaciones.
25.8 El resultado que nos refutamos a nosotros mismos
Esto es honestidad demostrada, no anunciada (Cap. 0). Al ver que el CKA re-asciende antes del salto, surgió una hipótesis tentadora: si la coordinación entre capas causa la generalización, entonces forzar \(\hat{O}_{01} \to 1\) (obligando a las capas a parecerse) debería provocar —o al menos no impedir— el grokking… y quizá lo contrario, impedirlo, demostraría que la señal es una palanca causal.
Lo probamos. Y el experimento nos refutó: al entrenar durante 20 000 pasos, 2 de cada 3 modelos con el CKA forzado siguieron grokking igualmente. La conclusión honesta:
El re-ascenso del CKA inter-capa es una señal predictiva / correlacional, no una palanca causal que puedas accionar para fabricar (o bloquear) la generalización.
Corregimos nuestra propia afirmación: pasó de “señal causal candidata” a “predictor temprano, sin causalidad demostrada”. Es exactamente el tipo de receta que el manual predica —seguir el dato aunque tumbe tu hipótesis favorita—.
tafagent no entrena modelos, pero incluye un detector de fase de cabezas de inducción (la receta de dinámica de entrenamiento, basada en \(\Delta\gamma\)): te indica si un modelo ya ha cruzado la transición en la que se forman los circuitos de copia/inducción —el pariente “de inferencia” de la formación de circuitos que aquí vemos durante el entrenamiento—. Útil para situar un modelo respecto a esa transición de fase sin tener que reentrenarlo.
25.9 Resumen
- Grokking (Power et al. 2022): en tareas algorítmicas, la red memoriza pronto (train→100 %, test al azar), pasa una meseta larga y generaliza de golpe mucho después.
- No es súbito por dentro (Nanda et al. 2023): aprende un algoritmo de Fourier que se forma gradualmente (memorización → formación del circuito → limpieza); la brusquedad es un artefacto de cuándo el circuito bueno gana.
- Por qué (Liu et al. 2022): el paisaje de pérdida frente a la norma de pesos (mecanismo “LU”) + weight decay arrastran de la solución memorizadora (norma alta) a la generalizadora (norma baja).
- Frontera 2024-2026: transiciones de fase con distintos parámetros de orden —entropía espectral, dimensión efectiva, defecto de conmutador—; dos de ellos ya predicen el salto.
- Nuestro piloto (Marín 2026): el CKA inter-capa \(\hat{O}_{01}\) cae y re-asciende ~3000 pasos antes del salto (16/16 vs 0/5; alcance = tareas tipo Fourier). Honesto: predecir no es novedad; lo nuestro es una señal simple, interna y barata, y es un piloto por validar.
- Nos refutamos: forzar el CKA→1 no impide el grokking (2/3 a 20 k pasos) → señal predictiva, no causal.
Siguiente: con esto cerramos la Parte III —la lente física sobre la atención—. La Parte IV abre el lado práctico: entrenar y ajustar modelos (pre-entrenamiento, fine-tuning, LoRA/PEFT, alineamiento), donde toda esta dinámica deja de ser curiosidad y se vuelve decisión de ingeniería.
25.10 Ejercicios
- La curva. Describe las tres fases del grokking en términos de las precisiones de train y test. ¿Por qué la lógica clásica del sobreajuste te diría que pares antes de que llegue el salto?
- No tan súbito. Según Nanda, ¿qué se está formando durante la meseta, y por qué el salto de test parece repentino aunque el mecanismo no lo sea?
- El motor. Explica el mecanismo “LU” de Omnigrok y el papel del weight decay. ¿Qué pasa si el weight decay es insuficiente?
- Honestidad I. ¿Por qué no afirmamos haber sido los primeros en predecir el grokking? ¿En qué consiste entonces nuestra aportación?
- Honestidad II. Teníamos la hipótesis de que el CKA era una palanca causal. ¿Qué experimento la puso a prueba, qué salió, y cómo cambió nuestra afirmación?
El estudio piloto completo —con los datos, las semillas, las tareas (suma/multiplicación modular, paridad \(k\)-dispersa) y el experimento de refutación del forzado del CKA— está depositado en abierto: Inter-Layer Alignment Re-Rise Predicts Grokking in Transformers: A Pilot Study (Zenodo).