18 Sumideros de atención y concentración
Dónde estamos. En el Cap. 13 conocimos el sumidero (esa columna brillante sobre el primer token). Ahora lo miramos a fondo —por qué se forma— y presentamos uno de nuestros resultados limpios: la concentración (el sumidero) y el decaimiento posicional (γ) son dos cosas independientes, no la misma. Es importante porque la literatura reciente las confunde a menudo, y separarlas evita conclusiones erróneas.
18.1 La idea en una frase
Que un modelo concentre mucha atención en pocos tokens (sumidero) y que su atención decaiga con la distancia (γ) son mecanismos distintos: puedes mover uno sin tocar el otro.
18.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- Sumidero de atención. Definición: la enorme cantidad de atención que casi todos los tokens vuelcan sobre unos pocos (típicamente el primero), aunque no aporten significado. En el transformer: es la “válvula de escape” del softmax —que obliga a cada fila a sumar 1—; sin un sitio donde descargar el peso sobrante, la atención se desestabilizaría.
- Massive activations. Definición: unos pocos valores enormes del estado oculto, muy por encima del resto. En el transformer: son la causa del sumidero —dirigen la atención hacia su token— y están ligadas a cómo el modelo comprime información.
- Masa de sumidero. Definición: la fracción de atención acumulada en esos pocos tokens, un número entre 0 y 1. En el transformer: mide cuán concentrada está la atención; es un fenómeno de amplitud, no de posición.
- Decaimiento posicional (γ). Definición: el exponente con que la atención cae con la distancia (
A(d)∝d^−γ). En el transformer: predice el alcance efectivo del modelo y la compresibilidad de su KV (Cap. 20); es un fenómeno posicional. - Base θ de RoPE. Definición: la constante que fija las frecuencias de la codificación rotatoria de posición. En el transformer: es la palanca que reescalamos en el experimento; mover θ cambia γ pero, como veremos, no toca el sumidero.
- Control within-model. Definición: comparar el mismo modelo consigo mismo cambiando una sola cosa. En el transformer: es lo que nos deja aislar la causa (θ) sin los factores cruzados de comparar modelos distintos.
- Independencia (⊥). Definición: dos mecanismos son independientes si mover uno no mueve el otro. En el transformer: nuestro resultado central —concentración y decaimiento son dos ejes separados—.
Con esto claro, vamos al porqué del sumidero y a la prueba de que γ y sumidero no son lo mismo.
18.3 Qué es un sumidero (y por qué se forma)
Recordemos (Cap. 13): el sumidero es la enorme atención que casi todos los tokens vuelcan sobre el primer token, aunque no signifique nada. La causa es estructural: como el softmax obliga a que cada fila sume 1, un token que no necesita mirar a nada en concreto tiene que descargar su peso en algún sitio —y los modelos aprenden a “aparcarlo” en los primeros tokens—.
La investigación reciente lo ha afinado:
- Es universal y se forma durante el pre-entrenamiento, no es un capricho del token BOS (Gu et al. 2025): aparece por la dinámica de optimización y los datos.
- Está causado por massive activations: unos pocos valores enormes del estado oculto (Sun et al. 2024) que dirigen la atención hacia su token. Y se ha mostrado que sumidero y compresión de representaciones son “dos caras de la misma moneda” (Queipo-de-Llano et al. 2025).
En una frase: el sumidero es un fenómeno de norma/amplitud (cuánta atención se acumula en un punto), no un fenómeno posicional (cómo se reparte con la distancia).
18.4 Nuestro resultado: γ ⊥ sumidero
Aquí está la aportación. (El símbolo ⊥ significa “independientes”: mover uno no mueve el otro.) Si concentración y decaimiento fueran lo mismo, mover uno movería el otro. Hicimos el experimento limpio —el que controla todo lo demás—: tomar un mismo modelo (pythia-1b) y reescalar solo su base θ de RoPE, un factor de 256×, sin tocar nada más.
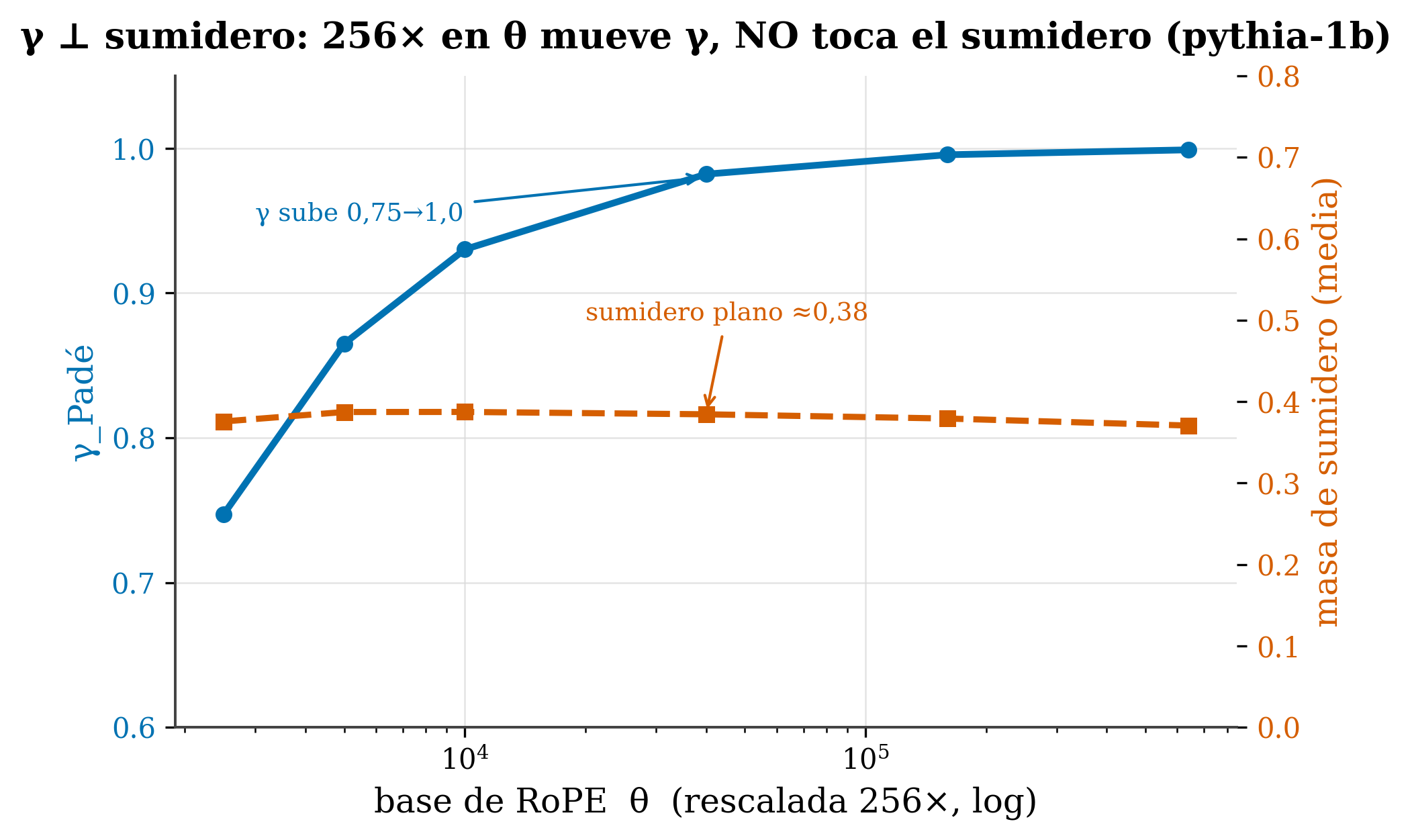
figures/make_fig17_orthogonality.py sobre data/gap1_ntk_rescale.csv.
El resultado es nítido: γ recorre casi todo su rango (0,75 → 0,999) mientras la masa de sumidero apenas se mueve (0,371 → 0,387). Misma palanca; un mecanismo cambia muchísimo, el otro nada. Conclusión:
El decaimiento posicional (γ) y la concentración estructural (sumidero) son mecanismos independientes. No son dos nombres de lo mismo, ni se siguen el uno al otro.
18.5 Por qué esto importa (y por qué within-model)
Dos motivos, y aquí enlaza con la honestidad del Cap. 16:
- Adjudica una confusión de la literatura 2026. Muchos trabajos hablan de “concentración” de la atención como si fuera lo mismo que su decaimiento con la distancia. No lo es: nuestro experimento lo separa con datos. Al medir o comparar atención, hay que tratarlas como dos ejes distintos.
- El control limpio es dentro del mismo modelo. En el Cap. 16 avisamos de que comparar el γ crudo entre modelos distintos mezcla factores. Aquí evitamos ese problema: mismo modelo, misma todo, solo cambia θ → cualquier efecto es causado por θ. Esa es la diferencia entre describir (atlas) y aislar una causa (experimento controlado).
Hay una analogía termodinámica tentadora (nuestra Parte III). Como el softmax conserva la masa de probabilidad (cada fila suma 1), bajo RoPE con decaimiento agudo (γ>1) el exceso de masa “tiene que condensar” en el estado base —el primer token—, igual que en una condensación de Bose-Einstein las partículas se acumulan en el nivel fundamental. La teoría da incluso una forma cerrada para la fracción condensada en función de γ:
\[ N_{\text{cond}} \;=\; 1 \;-\; \frac{1}{\zeta(\gamma)}\int_{1}^{L} d^{-\gamma}\,\mathrm{d}d \]
donde \(\zeta\) es la función zeta de Riemann y \(L\) la longitud de contexto.
Pero seamos quirúrgicos con lo que los datos sí y no dicen. La fórmula predice que el condensado depende de γ, y que la condensación arranca en el punto de Hagedorn (γ=1): en Phase A (γ<1) apenas habría condensado. Ahora bien, nuestro experimento within-model (Figura 18.1) barre γ de 0,75 a 0,999 —todo Phase A— y ahí encuentra un sumidero grande y plano (≈0,38). De eso se sigue, con cuidado:
- Lo que sí muestran los datos: hay un sumidero robusto en Phase A, donde la imagen de condensación predeciría poco → está en tensión con identificar el sumidero con el condensado BEC. Y, en línea con la tesis del capítulo (γ⊥sumidero), su masa no la fija γ.
- Lo que no podemos afirmar: el barrido limpio no entra en Phase B (γ>1), que es donde vive la predicción γ-dependiente de la BEC. Los pocos puntos con γ>1 que tenemos son cross-modelo y confundidos (Mistral ≈0,64, Qwen2.5 ≈0,02), no un test limpio.
Conclusión honesta: la BEC es una lente conceptual válida —explica por qué debe existir un sumidero (conservación de masa)—, pero su predicción cuantitativa γ-dependiente está sin respaldo y abierta, no confirmada ni limpiamente refutada. La usamos como intuición del mecanismo, no como número. ⚠ En disputa / pregunta abierta — falta un test within-model en γ>1.
18.6 La implicación práctica
Cuando analices la atención de un modelo, no mezcles dos preguntas:
- ¿Cuán concentrada está? → el sumidero, la masa en pocos tokens (un fenómeno de amplitud; se gestiona, p. ej., conservando unos pocos tokens iniciales como en StreamingLLM).
- ¿Cómo decae con la distancia? → γ (un fenómeno posicional; es lo que predice el alcance y la compresibilidad del KV, Cap. 20).
Confundirlas lleva a “arreglar” una creyendo que arreglas la otra.
¿Aparecen o desaparecen sumideros secundarios al barrer θ? Es una cuestión abierta que la propia literatura señala (los modelos de θ grande a veces carecen de ellos, y “la causa de fondo sigue siendo una pregunta abierta”, (On the discrepancy of secondary attention sinks in large-theta models 2025)). Tenemos el aparato para estudiarlo; lo marcamos como trabajo pendiente, no como resuelto.
tafagent reporta señales ligadas a la concentración (p. ej. peak_max_share y el η-régimen, que detecta cuándo el comportamiento es de tipo sumidero/SWA) además de γ. Verás en tu modelo que son ejes distintos: un modelo puede tener γ alto y poco sumidero, o al revés.
18.7 Resumen
- El sumidero es estructural (softmax suma 1) y de amplitud: causado por massive activations; universal, se forma en pre-entreno (Gu et al. 2025; Sun et al. 2024).
- Resultado limpio (nuestro): γ ⊥ masa-de-sumidero — reescalar θ 256× dentro del mismo modelo mueve γ (0,75→1,0) y deja el sumidero plano (~0,38) → mecanismos independientes.
- Por qué importa: separa una confusión común (concentración ≠ decaimiento); y el control within-model aísla la causa (frente a los confounds cross-modelo del Cap. 16).
- Abierto y honesto: los sumideros secundarios bajo θ-rescale son una pregunta sin resolver.
Siguiente (Capítulo 18): hemos hablado de la atención “normal” (densa). Pero hay toda una taxonomía de mecanismos de atención —sparse, local, lineal, GQA/MQA, MoE—, cada uno con su coste y su cuándo. El mapa comparativo que nadie tiene.
18.8 Ejercicios
- Independencia. Si concentración y decaimiento fueran el mismo fenómeno, ¿qué le habría pasado a la masa de sumidero al subir γ de 0,75 a 1,0? ¿Qué pasó en realidad?
- El control. ¿Por qué reescalar θ dentro del mismo modelo aísla la causa mejor que comparar dos modelos distintos?
- Dos ejes. Da un ejemplo de una decisión práctica que dependa del sumidero y otra que dependa de γ.
- Honestidad. ¿Qué cuestión sobre los sumideros dejamos explícitamente sin resolver?
El experimento within-model de reescalado de θ (γ ⊥ masa-de-sumidero) y sus datos están en abierto: Predicting How Transformers Attend (Zenodo).