15 Aliasing y las tres escalas de RoPE
Dónde estamos. En el Cap. 13 vimos que, al promediar, la atención pierde resolución con la distancia. ¿Por qué? La respuesta está en la geometría de RoPE: sus frecuencias tienen longitudes de onda, y las rápidas “se pliegan” (aliasing) enseguida. Este capítulo explica ese mecanismo y define las escalas que marcan hasta dónde el modelo distingue posiciones —el cimiento de la ley γ del Cap. 15—.
15.1 La idea en una frase
Cada par de dimensiones de RoPE gira a una velocidad distinta; los que giran rápido se repiten pronto y dejan de distinguir distancias (aliasing), así que cuanto más lejos, menos pares conservan señal posicional → se pierde resolución.
15.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- Frecuencia de RoPE (\(\omega_i\)). Definición: la velocidad a la que gira el par de dimensiones i, \(\omega_i = \theta^{-2i/d}\). En el transformer: es lo que codifica la posición de cada token; índices bajos giran rápido, altos casi no giran.
- Longitud de onda (\(\lambda_i\)). Definición: tras cuántas posiciones un par completa una vuelta entera y vuelve al mismo ángulo, \(\lambda_i = 2\pi\,\theta^{2i/d}\). En el transformer: marca el alcance de cada par; λ corta = grano fino local, λ larga = estructura de largo alcance.
- Base θ. Definición: el hiperparámetro de RoPE (10000 por defecto) que fija la escala de todas las longitudes de onda. En el transformer: la “perilla” que decide hasta qué distancia el modelo distingue posiciones; reescalarla extiende el contexto.
- Aliasing. Definición: cuando un par, pasada su λ, ya no distingue una distancia \(r\) de \(r+\lambda\) — ambas dan el mismo ángulo. En el transformer: es la causa raíz de que la posición se vuelva ambigua a lo lejos, no solo que el peso se amortigüe.
- \(n_{\rm active}(d)\). Definición: el número de pares que aún conservan señal posicional a distancia d. En el transformer: cuantifica cuánta resolución posicional le queda al modelo a cada distancia.
- Las tres escalas. Definición: \(\lambda_0\approx2\pi\) (grano local), \(T_{\rm cross}=2\pi\sqrt\theta\) (empieza a degradarse) y \(T_{\rm max}=2\pi\theta\) (se agota). En el transformer: son las distancias críticas, fijadas solo por θ, que en el Cap. 15 conectaremos con el exponente γ.
- Resolución posicional alcanzable. Definición: qué distancias el modelo puede distinguir, acotado por la geometría. En el transformer: la geometría pone el límite; cómo el modelo use cada banda dentro de él es cosa suya (no un decreto).
En resumen: la geometría de RoPE no impone cómo atiende el modelo, pero sí acota hasta dónde puede distinguir posiciones — el cimiento de la ley γ del próximo capítulo.
15.3 Las frecuencias de RoPE y su longitud de onda
Recuerda (Cap. 8): RoPE rota el par de dimensiones i a una frecuencia \(\omega_i = \theta^{-2i/d}\). A cada frecuencia le corresponde una longitud de onda:
\[ \lambda_i = 2\pi\,\theta^{\,2i/d} \]
Qué dice cada término:
- \(\lambda_i\) = tras cuántas posiciones ese par completa una vuelta entera (2π) y vuelve al mismo ángulo.
- \(\theta\) = la base de RoPE (10000 por defecto); más θ → longitudes de onda más largas en general.
- índice \(i\) bajo → λ corta (p. ej. el par 0 tiene λ≈2π≈6 posiciones): gira rápido. índice alto → λ larguísima: casi no gira en todo el contexto.
- \(d\) = la dimensión de la cabeza (\(d_{\rm head}\)); \(i\) numera el par de dimensiones (0, 1, 2…).
15.4 Aliasing: por qué se pierde resolución
Aquí está el quid. Un par que gira rápido completa vueltas enteras enseguida. Pasada su longitud de onda λ, ya no puede distinguir una distancia \(r\) de \(r+\lambda\): ambas dan el mismo ángulo, el mismo producto escalar. Ese par aliasa —se pliega— y deja de aportar información posicional única.
🧩 Analogía — la rueda de carreta en el cine. En las películas antiguas, las ruedas a veces parecen girar al revés o estar quietas: la cámara “muestrea” más lento que el giro real, así que un giro de 350° es indistinguible de uno de −10°. Los pares rápidos de RoPE son esa rueda: pasada su λ, “5 de distancia” y “5 + una vuelta” se ven idénticos.
A medida que crece la distancia, más pares (de longitud de onda creciente) van quedando plegados, así que cada vez menos pares conservan señal posicional inequívoca. Esa es la pérdida de resolución, y no es solo que el peso se amortigüe: es que la posición se vuelve ambigua.
15.5 Las tres escalas
Podemos contar cuántos pares siguen “vivos” a distancia d. Esa cuenta (de nuestro Paper I (Marín 2026)) es:
\[ n_{\rm active}(d) = \frac{d_{\rm head}}{2}\left(1 - \log_\theta\!\frac{d}{2\pi}\right) \]
- \(d_{\rm head}/2\) = número total de pares de frecuencia en una cabeza.
- \(\log_\theta(d/2\pi)\) (el logaritmo en base θ) = qué fracción de esos pares ya ha aliasado a distancia d. (Aquí d es la distancia entre tokens, no la dimensión de la cabeza \(d_{\rm head}\) de la fórmula de arriba.)
- \((1-\dots)\) = la fracción que sobrevive.
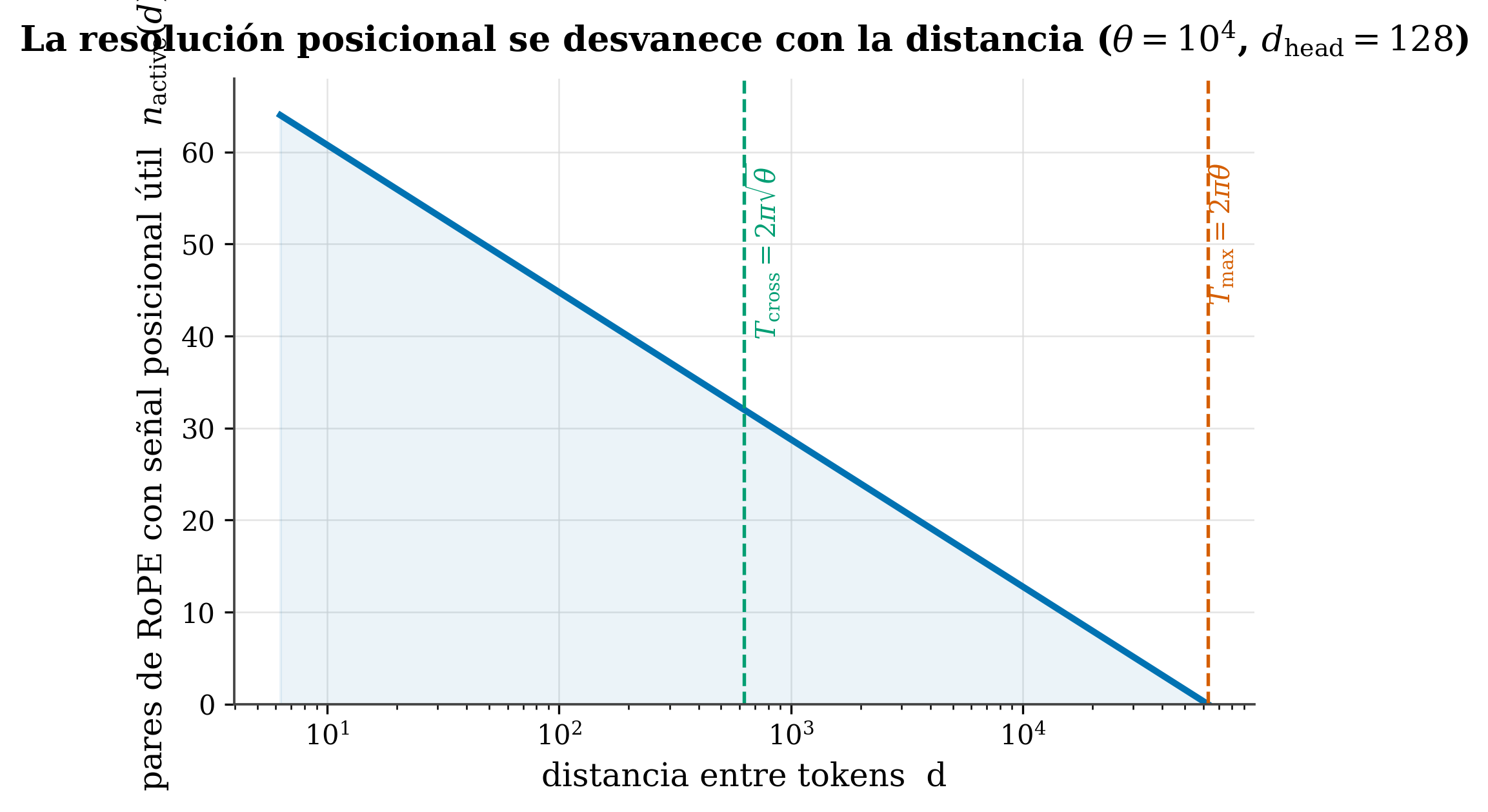
Esto define tres escalas naturales (con θ=10⁴):
- \(T_{\rm cross} = 2\pi\sqrt{\theta}\) (≈ 628): la escala donde la resolución empieza a degradarse apreciablemente.
- \(T_{\rm max} = 2\pi\theta\) (≈ 62 832): la longitud de onda del par más lento; más allá, ningún par conserva señal posicional inequívoca (\(n_{\rm active}\to 0\)).
- (Y la más corta, \(\lambda_0 \approx 2\pi\), el grano fino local.)
Estas escalas, fijadas solo por θ y la geometría, son las que en el Cap. 15 conectaremos con el exponente de decaimiento γ.
Cuidado con sobrevender esto. Un trabajo reciente (Round and Round We Go (Barbero et al. 2024)) muestra que RoPE no impone un decaimiento monótono: con consultas/claves reales no hay decaimiento garantizado, y de hecho los modelos usan las bajas frecuencias para emparejar contenido casi sin importar la posición. Así que no diremos “RoPE obliga a la atención a decaer”. Lo que sí sostenemos —y es compatible con ese trabajo (su Teorema 6.1 prueba que esos canales de baja frecuencia no son robustos en contexto largo)— es que la geometría acota la resolución posicional alcanzable: marca qué distancias pueden distinguirse. Cómo use el modelo cada banda dentro de ese límite es cosa suya. Por eso, en el Cap. 15, γ será un descriptor medido de modelos entrenados, no una ley impuesta por decreto geométrico.
15.6 Un puntero: estirar las longitudes de onda
Como las λ dependen de θ, reescalar θ (NTK-aware, YaRN) las estira —y con ellas el alcance de distancias que el modelo distingue—. Es la base de la extensión de contexto (Cap. 19): mover las escalas para que el modelo funcione más allá de su longitud de entrenamiento.
15.7 Resumen
- Cada par de RoPE tiene una longitud de onda \(\lambda_i = 2\pi\,\theta^{2i/d}\): índice bajo = λ corta (gira rápido), alto = λ larga.
- Aliasing: pasada su λ, un par no distingue \(r\) de \(r+\lambda\) → deja de dar posición única. A más distancia, más pares plegados → menos resolución.
- \(n_{\rm active}(d)\) cuenta los pares vivos; define \(T_{\rm cross}=2\pi\sqrt\theta\) (empieza a degradarse) y \(T_{\rm max}=2\pi\theta\) (se agota).
- Honesto: la geometría acota la resolución alcanzable; NO impone decaimiento (cf. Round and Round (Barbero et al. 2024)). γ será un descriptor medido, no un decreto.
- Reescalar θ estira las λ → extiende el contexto (Cap. 19).
Siguiente (Capítulo 15): con la geometría clara, llegamos al corazón de nuestro trabajo — la ley de decaimiento A(d) ∝ d^−γ y, sobre todo, cómo predecir γ.
15.8 Ejercicios
- Longitud de onda. Con θ=10000 y d=64, ¿qué par gira más rápido, el de índice i=0 o i=30? ¿Cuál aliasa antes?
- Aliasing. Explica con la analogía de la rueda por qué un par de RoPE no puede distinguir una distancia de otra que difiere en exactamente una longitud de onda.
- Las escalas. ¿Qué representa \(T_{\rm max}=2\pi\theta\)? ¿Qué le pasa a \(n_{\rm active}\) ahí?
- Honestidad. ¿Por qué decimos que la geometría “acota la resolución” en lugar de “impone el decaimiento”? (Piensa en qué demostró Round and Round.)