5 La atención como agregación ponderada
Dónde estamos. Ya tenemos cada token convertido en un vector viajando por el flujo residual. Llega el acto central —el que da nombre al libro—: la atención, la regla con la que cada token decide a cuáles de los demás hacer caso y mezcla su información. Al terminar sabrás calcular una atención a mano, programarla en ~15 líneas, y distinguir qué afirmaciones populares sobre ella son ciertas, cuáles folclore y cuáles marketing.
5.1 La idea en una frase
Cada token se actualiza convirtiéndose en un promedio ponderado de la información de los demás tokens, donde los pesos los decide el propio modelo sobre la marcha según qué es relevante.
🧩 Analogía. Estás en una reunión y alguien hace una pregunta. Miras alrededor: un par de personas dominan el tema, el resto no tanto. Sin pensarlo, ponderas lo que oyes —escuchas con atención a quien sabe, ignoras a medias al resto— y tu respuesta sale como una mezcla, dominada por quien importa. Eso es exactamente lo que hace la atención con cada palabra: mezcla información de las demás, dando más peso a las relevantes. Lo único especial es que el modelo decide “quién es relevante” al instante, a partir de las propias palabras.
5.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- Agregación ponderada. Definición: construir la salida de un token como un promedio de la información de los demás, pesando más a los relevantes. En el transformer: es lo que hace la atención; el mecanismo por el que la información viaja entre palabras.
- Consulta, clave y valor (Q, K, V). Definición: tres vectores que el modelo obtiene de cada token mediante tablas aprendidas —qué busca, qué anuncia y qué entrega—. En el transformer: separar en Q, K y V es lo que permite aprender qué conectar con qué en lugar de seguir una regla fija.
- Producto escalar. Definición: una forma de medir cuánto se parecen dos listas de números (se multiplican pareja a pareja y se suman). En el transformer: compara la consulta de un token con la clave de otro; si sale grande, “se buscan” → peso alto.
- Logits / puntuaciones. Definición: las comparaciones en bruto \(q_i\cdot k_j\) antes de normalizar. En el transformer: son la materia prima de los pesos; el softmax las convierte en una mezcla.
- Escalado \(1/\sqrt{d_k}\). Definición: dividir las puntuaciones por la raíz de la dimensión de las claves. En el transformer: mantiene los logits en un rango manejable para que el softmax no se sature sin importar el ancho del modelo; es una constante derivable, no mágica.
- Softmax. Definición: la función que convierte una fila de puntuaciones en pesos no negativos que suman 1. En el transformer: impone el “presupuesto de 1” (atender más a uno implica atender menos a otro) y hace que la mezcla sea un promedio de verdad.
- Mapa de atención (\(A\)). Definición: la matriz \(n\times n\) de pesos, lo que se visualiza como mapa de calor. En el transformer: dice adónde va el peso; su tamaño cuadrado es el origen del coste O(n²) que encarece el contexto largo.
- Máscara causal. Definición: poner a \(-\infty\) las puntuaciones hacia el futuro antes del softmax. En el transformer: en modelos generativos (tipo GPT) impide que un token mire los que vienen después, condición para generar texto palabra a palabra.
Con esto en mano, los desarrollamos.
5.3 Para qué sirve la atención (su papel en el transformer)
Antes de las fórmulas, lo más importante: ¿qué trabajo hace la atención dentro del modelo, y por qué el transformer la necesita?
La atención es el único lugar donde la información viaja entre palabras. Todo lo demás del transformer —en particular la red feed-forward (Cap. 6)— procesa cada palabra por separado, como islas. Sin atención, la palabra “él” no podría enterarse de a quién se refiere, y “banco” no sabría si está junto a un río o en la Bolsa: cada token se quedaría con su significado de diccionario, sin contexto.
Su función, en una frase: dar contexto a cada palabra dejándola recoger información de las demás. Es lo que convierte una bolsa de palabras sueltas en un texto entendido. Por eso es el corazón del transformer (y de este libro): lo bien que un modelo atiende es, en gran medida, lo bien que entiende.
5.4 La fórmula de la mezcla
En símbolos, la nueva representación del token i es:
\[ \text{salida}_i = \sum_j \alpha_{ij}\, v_j \tag{5.1}\]
Qué hace cada término:
- \(v_j\) = el valor que aporta el token j (qué información entrega si se le atiende).
- \(\alpha_{ij}\) = el peso: cuánto escucha el token i al token j. Es no negativo y todos los pesos de i suman 1.
- \(\sum_j\) = sumamos sobre todos los tokens j → la salida es una mezcla.
Todo el arte está en calcular los pesos \(\alpha_{ij}\). Veámoslo por partes.
5.5 Consultas, claves y valores (Q, K, V)
¿De dónde salen los pesos? Cada vector de token se transforma en tres vectores distintos mediante tres “recetas” que el modelo aprende:
\[ q_j = W_Q\,x_j, \qquad k_j = W_K\,x_j, \qquad v_j = W_V\,x_j \]
No te asustes con la fórmula: \(W_Q, W_K, W_V\) son tablas de números que el modelo ha aprendido, y “\(W\,x\)” (multiplicar el token por la tabla) es solo la forma matemática de decir transforma este token en su versión consulta, clave o valor. No hace falta saber multiplicar matrices para entender la idea.
La metáfora que ayuda de verdad:
- Consulta \(q_i\) — “¿qué está buscando el token i?”
- Clave \(k_j\) — “¿qué anuncia de sí mismo el token j?”
- Valor \(v_j\) — “¿qué entrega el token j si se le atiende?”
El token i compara su consulta con cada clave mediante un producto escalar \(q_i \cdot k_j\). (El producto escalar es solo una manera de medir cuánto se parecen dos listas de números: se multiplican pareja a pareja y se suman; si ambas “apuntan a lo mismo”, sale un número grande.) Si sale grande, “j anuncia lo que i busca” → peso alto. Esas puntuaciones en bruto se llaman logits; el softmax las convertirá en los pesos.
¿Para qué sirve separar en consulta, clave y valor? Es lo que permite al modelo aprender qué conectar con qué, en vez de seguir una regla fija (“mira siempre a la palabra anterior”). Las tablas \(W_Q, W_K, W_V\) se ajustan durante el entrenamiento para que cada token busque y anuncie justo lo que conviene a la tarea —por eso un modelo aprende, por ejemplo, a conectar un pronombre con su referente—.
Que Q, K, V sean tres proyecciones aprendidas distintas del mismo vector es el mecanismo real, no una simplificación: es lo que hace que la atención dependa del contenido y no sea fija.
5.6 Por qué se divide entre √d_k
Antes del softmax, la puntuación se escala dividiéndola por la raíz de la dimensión de las claves, \(d_k\):
\[ s_{ij} = \frac{q_i \cdot k_j}{\sqrt{d_k}} \tag{5.2}\]
Qué hace cada término:
- \(q_i \cdot k_j\) = la similitud bruta entre lo que i busca y lo que j anuncia (una suma de \(d_k\) productos).
- \(d_k\) = cuántas dimensiones tienen las consultas/claves.
- \(1/\sqrt{d_k}\) = el factor de escala que mantiene la puntuación en un rango manejable sin importar cómo de ancho sea el modelo.
🧩 Analogía. Piensa en el producto escalar como un recuento: puntúas cada una de las \(d_k\) dimensiones y las sumas. Igual que un examen con más preguntas tiene una nota total mayor, una suma sobre más dimensiones da números más grandes. Dividimos por \(\sqrt{d_k}\) para devolver la escala a “lo que vale una dimensión”, sea cual sea el ancho del modelo.
¿Por qué importa? Si las puntuaciones se hacen enormes, el softmax se satura —pone casi todo el peso en un solo token y deja de aprender—. La Figura 5.1 lo muestra con vectores aleatorios reales.
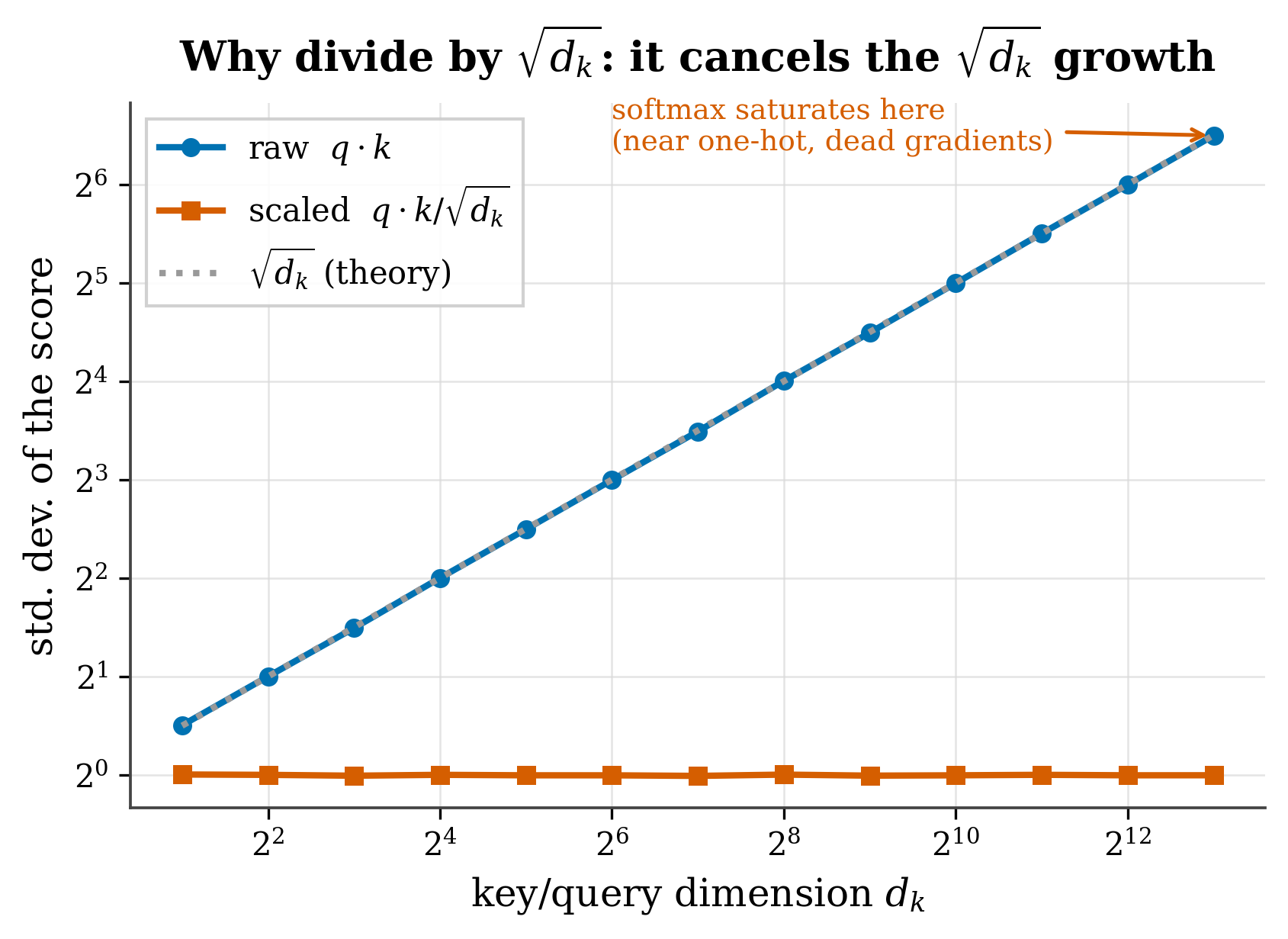
figures/make_fig03_3_scaling.py (semilla 0).
Si las componentes de \(q_i\) y \(k_j\) son independientes con media 0 y varianza 1, su producto escalar es una suma de \(d_k\) términos de varianza ≈1. Como son independientes, la varianza de la suma crece como \(d_k\) y la desviación típica como \(\sqrt{d_k}\). Dividir por \(\sqrt{d_k}\) devuelve los logits a varianza unidad. Es una constante derivable, no un número mágico.
5.7 Softmax: de puntuaciones a pesos
El softmax convierte una fila de puntuaciones en pesos no negativos que suman 1:
\[ \alpha_{ij} = \frac{e^{s_{ij}}}{\sum_{j'} e^{s_{ij'}}} \tag{5.3}\]
Qué hace cada término:
- \(e^{s_{ij}}\) = la exponencial convierte cualquier puntuación en un número positivo, y amplifica las diferencias (una puntuación algo mayor se lleva bastante más peso).
- \(\sum_{j'} e^{s_{ij'}}\) = el denominador (la suma de todas) normaliza, de modo que los pesos sumen exactamente 1.
🧩 Analogía — el presupuesto de 1. Cada token tiene 1 € de atención que repartir entre todos. Una puntuación mayor compra una porción mayor, pero las porciones siempre suman 1 €: atender más a uno implica necesariamente atender menos a otros. Recuerda esta competencia para los sumideros de atención (Parte II).
¿Para qué sirve el softmax aquí? Para que la mezcla sea un promedio de verdad: convierte comparaciones en bruto (que podrían ser negativas o enormes) en pesos positivos que suman 1. Sin él, la “mezcla” sería una suma de números sin escala, no un promedio interpretable.
Hay una lectura profunda: el softmax es la distribución de máxima entropía (la que menos asume) compatible con una puntuación esperada dada —la misma idea que en física da la distribución de Boltzmann—. Esto no es anecdótico: en la Parte II veremos que combinar esta máxima entropía con la geometría de RoPE explica por qué la atención decae como una ley de potencia —uno de nuestros resultados—.
Suman 1 y son no negativos, así que formalmente son una distribución sobre los tokens —pero tratarlos como las creencias del modelo es injustificado—. Léelos como coeficientes de mezcla, no como probabilidades.
5.8 La operación completa, en matrices
En la práctica esto se hace para todos los tokens a la vez. (Apilar los vectores “en una matriz” es solo ponerlos en filas, uno por token, para hacer todas las comparaciones de golpe en lugar de una a una.)
\[ \text{Atención}(Q,K,V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right) V \tag{5.4}\]
Qué hace cada pieza:
- \(QK^\top\) = la matriz \(n\times n\) de todas las puntuaciones por pares (el
⊤es la transpuesta: gira la tabla de claves para poder enfrentar cada consulta con cada clave) (cada consulta contra cada clave). - softmax(·) (por filas) = convierte cada fila en pesos que suman 1 → es el mapa de atención \(A\), lo que se visualiza como mapa de calor.
- \(\cdots V\) = multiplicar por los valores produce la salida: cada token, ya como mezcla ponderada.
Fíjate en el tamaño de \(A\): \(n \times n\). Ese cuadrado es el origen del coste cuadrático de la atención y la razón de que el contexto largo sea caro —el tema central de la Parte II—.
Máscara causal. En un modelo generativo (tipo GPT), un token solo puede atender a sí mismo y a los anteriores. Se impone poniendo \(s_{ij} = -\infty\) para \(j > i\) antes del softmax (así esos pesos se vuelven 0). Lo vemos en detalle en el Capítulo 9.
5.9 Ejemplo a mano
Con \(d_k = 2\) y tres tokens (vectores ya proyectados):
q₂ = [1, 0] # calculamos la salida del token 2
k₁ = [1, 0] v₁ = [10, 0]
k₂ = [0, 1] v₂ = [0, 10]
k₃ = [1, 1] v₃ = [5, 5]- Puntuaciones \(q_2\cdot k_j\): \(1,\,0,\,1\).
- Escala entre \(\sqrt2≈1.414\): \(0.707,\,0,\,0.707\).
- Softmax: \(e^{0.707}=2.028,\ e^0=1,\ e^{0.707}=2.028\); suma \(=5.056\) → \(\alpha=[0.401,\,0.198,\,0.401]\).
- Mezcla: \(\text{salida}_2 = 0.401[10,0]+0.198[0,10]+0.401[5,5]=[6.015,\,3.985]\).
El token 2 “miró sobre todo a los tokens 1 y 3” (claves coincidentes) y produjo una mezcla dominada por sus valores.
5.10 Desde cero en código
import torch
import torch.nn.functional as F
def atencion(Q, K, V, causal=False):
# Q,K,V: (n, d) — una fila por token
d_k = Q.shape[-1]
scores = (Q @ K.transpose(-2, -1)) / d_k**0.5 # (n, n) logits
if causal: # enmascarar el futuro
n = scores.shape[-1]
mask = torch.triu(torch.ones(n, n), diagonal=1).bool()
scores = scores.masked_fill(mask, float('-inf'))
A = F.softmax(scores, dim=-1) # (n, n) mapa de atención
return A @ V, A
Q = torch.tensor([[1., 0.]])
K = torch.tensor([[1., 0.], [0., 1.], [1., 1.]])
V = torch.tensor([[10., 0.], [0., 10.], [5., 5.]])
out, A = atencion(Q, K, V)
print(A.round(decimals=3)) # tensor([[0.401, 0.198, 0.401]])
print(out.round(decimals=3)) # tensor([[6.015, 3.985]])Quince líneas reproducen el cálculo a mano. Todo lo demás —multi-cabeza (Cap. 5), FFN (Cap. 6), normalización (Cap. 7)— envuelve este núcleo.
Para ver que la atención no es un borrón uniforme, abre un visualizador interactivo como BertViz (Vig 2019) o el Transformer Explainer (poloclub): carga una frase y observa cómo el peso se concentra en pocas posiciones —a menudo el primer token, el sumidero del Cap. 13—. Más adelante, en la Parte II, usaremos nuestro tafagent para medir ese comportamiento con el exponente γ.
5.11 Lo que un mapa de atención NO te dice
Es tentador leer un mapa de calor como la explicación del modelo —“predijo X porque atendió a Y”—. Esa inferencia no es válida en general.
La salida de una capa es \(A\,V\) más el residual más la MLP; la información también fluye por los valores y por capas posteriores. Un token puede recibir mucha atención y aportar poco (si su \(\lVert v_j\rVert\) —la longitud o magnitud de su vector valor— es pequeña), o recibir poca y aun así importar por la vía residual. Empíricamente, los pesos a menudo no son fieles a lo que el modelo usa. Trata los mapas como un diagnóstico, no como una prueba de razonamiento.
Son genuinamente útiles —en la Parte II los usamos para medir el decaimiento— pero como medidas de adónde va el peso, no como certificados de por qué el modelo decidió algo.
5.12 Resumen
- La atención convierte cada token en un promedio ponderado aprendido de los valores (Ecuación 5.1).
- Los pesos salen del producto escalar escalado de consultas y claves
- y del softmax (Ecuación 5.3).
- El \(1/\sqrt{d_k}\) es una normalización de varianza derivable (Figura 5.1).
- El softmax impone el presupuesto de 1 (competencia) y es máxima entropía —semilla de nuestra ley de decaimiento de la Parte II—.
- El mapa de atención es \(n\times n\) → coste cuadrático (por qué el contexto largo es difícil).
- Los pesos son coeficientes de mezcla, no probabilidades, y no explican las decisiones del modelo.
Siguiente (Capítulo 5): una sola atención es miope. La atención multi-cabeza corre varias en paralelo para mirar varias cosas a la vez.
5.13 Ejercicios
- A mano. Recalcula el ejemplo con \(q_2=[0,2]\). ¿Qué token domina ahora la salida, y por qué?
- El escalado. Genera \(Q,K\in\mathbb{R}^{1\times d}\) aleatorios para \(d=4,64,4096\). Imprime la desviación típica de \(QK^\top\) con y sin el factor \(1/\sqrt d\). Confirma que la no escalada crece como \(\sqrt d\).
- Saturación. Multiplica los logits por 10 antes del softmax. ¿Qué le pasa a \(A\)? Relaciónalo con la “temperatura”.
- Fidelidad. Construye un ejemplo de 2 tokens donde i atienda 0.99 a j y, aun así, cambiar \(v_j\) apenas cambie la salida. (Pista: \(\lVert v_j\rVert\) minúsculo.)