4 Embeddings y el flujo residual
Dónde estamos. En el capítulo anterior convertimos el texto en tokens: números enteros. Pero un número como 15496 no le dice nada al modelo sobre el significado —15496 no está “más cerca” de 15497 que de 42—. Este capítulo da el segundo paso: convertir cada token en un vector (su embedding) que sí captura relaciones, y colocarlo en el flujo residual, la “memoria compartida” por la que viaja la información dentro del modelo. Al terminar entenderás por qué los modelos usan vectores, cómo capturan significado, y cuál es el verdadero canal de comunicación entre capas.
4.1 La idea en una frase
Cada token se sustituye por un vector de números aprendido —su embedding—, y todos esos vectores viajan por un canal común, el flujo residual, donde cada capa lee y va sumando información sin borrar lo anterior.
4.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- Embedding. Definición: el vector de números aprendido que representa a un token. En el transformer: convierte un entero sin significado en algo con distancia y dirección, que es lo que el modelo puede procesar.
- Matriz de embeddings (
E). Definición: la gran tabla (vocabulario ×d_model) con una fila por token. En el transformer: el token-ID selecciona su fila; es donde viven todos los embeddings de entrada. d_model. Definición: la dimensión de cada vector y, por tanto, el “ancho” del flujo residual. En el transformer: fija cuánta capacidad de distinción tiene el modelo; más ancho = más finura a cambio de más cómputo.- Significado como dirección. Definición: la idea de que las relaciones (género, plural…) viven en direcciones del espacio, no en ejes sueltos (rey − hombre + mujer ≈ reina). En el transformer: es la geometría que un entero no da y que hace útiles a los vectores.
- Estático vs. contextual. Definición: el embedding de entrada es fijo por token; tras pasar por las capas, se contextualiza. En el transformer: “banco del río” y “banco central” parten del mismo vector, pero las capas lo separan; la contextualización no está en
E, sino en lo que se escribe encima. - Flujo residual (residual stream). Definición: el canal común —una “pizarra compartida”— por el que viaja el vector de cada token. En el transformer: el embedding lo inicializa y cada capa lee y SUMA (no borra), así que la información previa persiste y se puede combinar más adelante.
- Conexión residual. Definición: la suma \(x \leftarrow x + f(x)\) que añade la contribución de cada bloque en lugar de reemplazar. En el transformer: es lo que permite entrenar modelos muy profundos sin que la señal se pierda.
- Posición. Definición: información del orden que se añade al embedding, porque la atención por sí sola es permutación-invariante. En el transformer: sin ella el modelo no distinguiría “perro muerde hombre” de “hombre muerde perro”; los modelos modernos la inyectan con RoPE (Cap. 8).
Con esto en mano, los desarrollamos.
4.3 Qué es un embedding
¿Cómo pasamos de un entero a algo con significado? El modelo guarda una gran tabla, la matriz de embeddings E, de forma (tamaño_vocabulario × d_model): una fila por cada token del vocabulario, y cada fila es un vector de d_model números. El token-ID simplemente selecciona su fila:
import torch, torch.nn as nn
vocab, d_model = 50257, 768 # p.ej. GPT-2
E = nn.Embedding(vocab, d_model) # la matriz (se aprende)
ids = torch.tensor([15496, 1917, 0]) # "Hola", " mundo", "!"
vecs = E(ids) # (3, 768): un vector por token
print(vecs.shape) # torch.Size([3, 768])Matemáticamente es equivalente a multiplicar un vector one-hot (todo ceros menos un 1 en la posición del token) por E —pero en la práctica es solo “ve a la fila número id”—.
4.4 Por qué un vector y no el entero
¿No bastaría con el número del token? No, porque los enteros no tienen noción de parecido: el 47 no es “más similar” al 48 que al 9000. En cambio, un vector vive en un espacio donde sí hay distancia y dirección: tokens con significado parecido pueden acabar cerca, y relaciones (género, plural, tiempo verbal…) pueden corresponder a direcciones. Esa geometría es lo que el modelo necesita y un entero no da.
4.5 Cómo se aprenden
Los embeddings no se fabrican a mano ni se descargan: empiezan con valores aleatorios y se ajustan junto con todo el modelo durante el entrenamiento, por retropropagación, como cualquier otro peso. La estructura semántica emerge sola al entrenar para predecir texto.
4.6 El significado vive en direcciones
La intuición viene de antes de los transformers. La hipótesis distribucional (Firth 1957) lo resume: “conocerás una palabra por la compañía que tiene” —las palabras que aparecen en contextos parecidos significan cosas parecidas—. Métodos como word2vec (Mikolov et al. 2013) y GloVe (Pennington et al. 2014) la llevaron a vectores, con el ejemplo ya célebre:
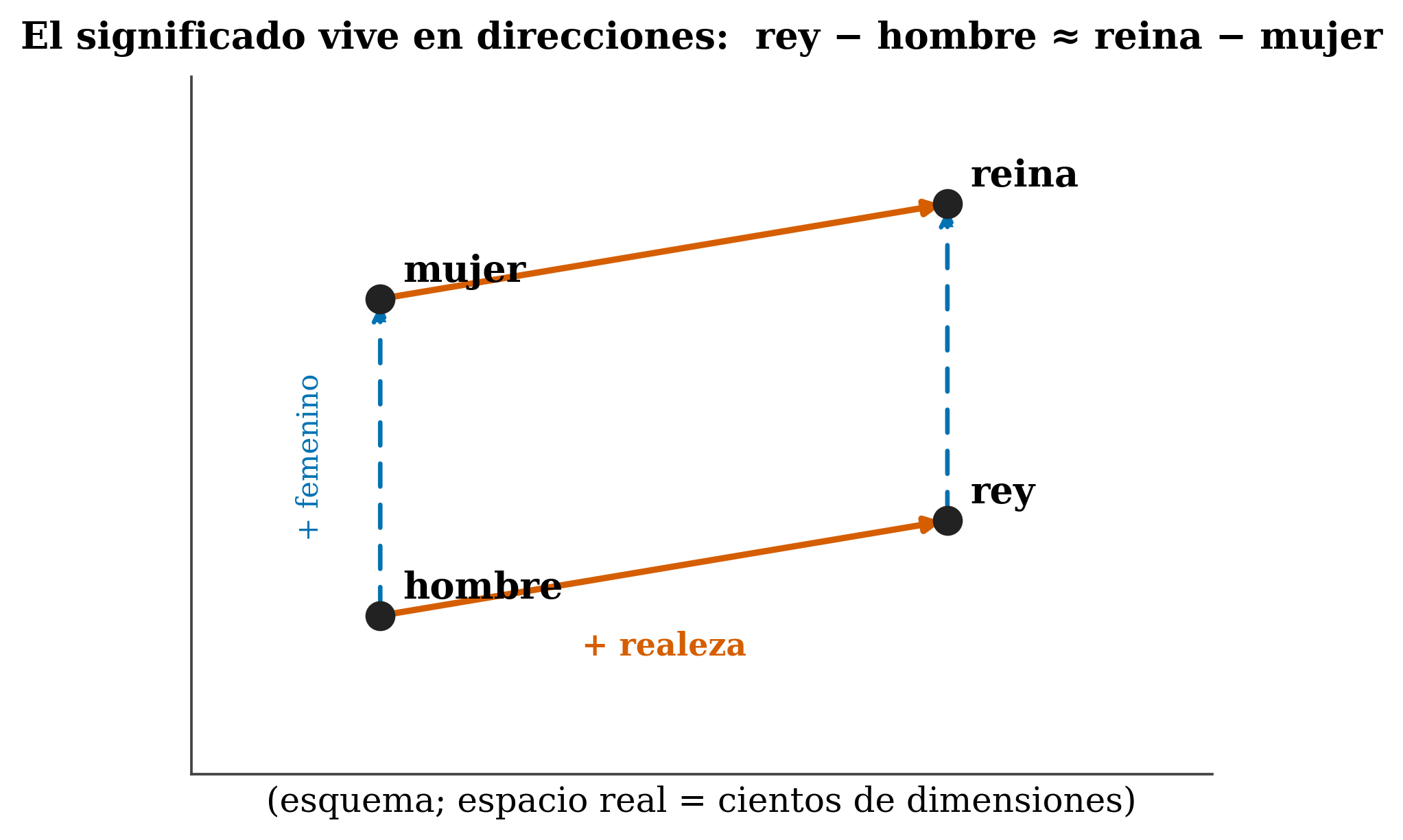
rey − hombre + mujer ≈ reina. En un modelo real el espacio tiene cientos de dimensiones; esto es solo una intuición visual.
\[ \text{vec}(\text{rey}) - \text{vec}(\text{hombre}) + \text{vec}(\text{mujer}) \approx \text{vec}(\text{reina}) \]
La analogía es ilustrativa, no una ley exacta: el ≈ no es =, y en la práctica no funciona perfecto para todas las palabras. Y cuidado: las dimensiones sueltas no son interpretables una a una; el significado vive en direcciones del espacio, no en ejes concretos. Que una dimensión sea “la del género” es la excepción de juguete, no la regla.
4.7 El matiz que casi todos confunden: estático vs. contextual
Aquí hay una sutileza importante. Los vectores de word2vec son estáticos: la palabra “banco” tiene un solo vector, dé igual la frase. Los embeddings de entrada de un transformer (la fila de E) también son estáticos por token.
La diferencia clave: en un transformer, ese vector estático se contextualiza al atravesar las capas. Tras la atención, el vector de “banco” en “banco del río” ya difiere del de “banco central”. La contextualización no está en
E; está en lo que las capas van escribiendo encima —y eso nos lleva al flujo residual—.
4.8 El flujo residual: la pizarra compartida
¿Por dónde viaja y se acumula toda esa información? Por el flujo residual (el residual stream), el concepto que mejor explica cómo funciona un transformer por dentro (Elhage et al. 2021).
🧩 Analogía — una cinta transportadora con una pizarra compartida. Cada token entra en la cinta con una nota inicial: su embedding. En cada estación (capa), los operarios —la atención y la red feed-forward— leen lo que hay en la pizarra y añaden sus anotaciones, sin borrar nada. Al final de la cinta, un lector traduce la pizarra acumulada en la predicción. Nadie tiene memoria propia: todo se comparte en esa pizarra.
En fórmulas, cada bloque suma su contribución al vector que viaja (de ahí “residual”):
\[ x \leftarrow x + \text{atención}(x), \qquad x \leftarrow x + \text{FFN}(x) \]
Tres ideas que conviene retener:
- El embedding inicializa el flujo (es el valor de partida).
- Cada capa lee y suma (no reemplaza), así que la información previa persiste y se puede combinar más adelante.
- El valor final del flujo se “desembebe” (se proyecta de vuelta al vocabulario) para producir la predicción (Capítulo 12).
Esta escritura aditiva viene de las conexiones residuales de las ResNets (He et al. 2016), y es justo lo que permite entrenar modelos muy profundos sin que la señal se pierda.
Muchos modelos comparten la matriz de embeddings de entrada con la de salida (la que convierte el vector final en logits sobre el vocabulario): es el mismo E usado en los dos extremos (Press y Wolf 2017). Ventajas: menos parámetros y, a menudo, mejor rendimiento. Tiene sentido: si E[i] representa al token i a la entrada, también sirve para puntuarlo a la salida.
4.9 ¿Cómo de grande es d_model?
d_model (la dimensión de cada vector y, por tanto, el “ancho” del flujo residual) ha crecido con los modelos:
| Modelo | d_model |
|---|---|
| Transformer original (2017) | 512 |
| GPT-2 small / BERT-base | 768 |
| LLaMA-2-7B | 4096 |
| GPT-3 (175B) | 12288 |
Más d_model = más capacidad para hacer distinciones finas (y un flujo residual más ancho), pero también más parámetros y más cómputo. Es otro compromiso, como el tamaño de vocabulario del capítulo anterior.
4.10 Y la posición, ¿dónde entra?
Un detalle que cerramos aquí y abrimos del todo más adelante: tal cual, la atención no sabe el orden de los tokens (es “permutación-invariante”). Para que el orden importe, se añade información de posición al embedding de cada token. El Transformer original usó posiciones sinusoidales; GPT-2 y BERT, aprendidas; los modelos modernos usan RoPE —que veremos en detalle en el Capítulo 8—.
4.11 Resumen
- Un embedding es el vector aprendido que representa a un token; vive en la matriz
E(vocabulario ×d_model), y el token-ID selecciona su fila. - Se usan vectores (no el entero) porque dan distancia y dirección: el significado vive en direcciones (rey − hombre ≈ reina − mujer), no en ejes sueltos.
- Los embeddings de entrada son estáticos por token; las capas los contextualizan después.
- El flujo residual es el canal común: el embedding lo inicializa, cada capa lee y SUMA (no borra), y el valor final se desembebe para predecir.
d_model(ancho del flujo) va de 512 a 12288: más capacidad a cambio de más cómputo.
Siguiente (Capítulo 4): ya tenemos los vectores en el flujo. Toca el corazón del libro —cómo la atención deja que cada token mire a los demás y mezcle su información—.
4.12 Ejercicios
- La tabla
E. Si el vocabulario tiene 50.000 tokens yd_model = 768, ¿cuántos números (parámetros) tiene la matriz de embeddings? ¿Y cond_model = 4096? - Estático vs. contextual. Explica con tus palabras por qué “banco” tiene un embedding de entrada pero distintas representaciones en capas profundas según la frase.
- Aditivo. En el flujo residual,
x ← x + FFN(x). ¿Qué ventaja tiene sumar en lugar de reemplazarx? (Pista: ¿qué pasa con la información de capas anteriores?) - Direcciones. Si
vec(París) − vec(Francia) + vec(España) ≈ vec(?), ¿qué palabra esperarías y por qué?