21 Compresión de KV-cache en práctica
Dónde estamos. Cierre de la Parte II. El KV-cache (Cap. 12) crece sin parar y es el cuello de botella del contexto largo. Aquí vemos cómo lo comprime el campo —y nuestra aportación: una ventana derivada de γ, sin parámetros que ajustar—. Y, como siempre, qué parte de esto está validado y qué no.
21.1 La idea en una frase
Cuánto se puede comprimir el KV-cache de un modelo lo decide su exponente γ: con γ>1 (cola ligera) una ventana finita captura casi toda la atención; con γ<1 (cola pesada) no —y esa ventana se puede calcular en forma cerrada—.
21.2 Conceptos clave y su papel en el transformer
Antes de entrar en detalle, definimos los términos de este capítulo y para qué sirve cada uno dentro de un transformer:
- KV-cache. Definición: la memoria que guarda las claves (K) y valores (V) de cada token pasado, por capa y por cabeza, para no recomputarlos al generar. En el transformer: crece O(n) con el contexto y es el cuello de botella de memoria en contexto largo.
- Compresión de KV. Definición: decidir qué K/V conservar y cuáles descartar, fusionar o cuantizar. En el transformer: permite servir contextos largos sin que la caché ahogue la memoria de la GPU.
- Exponente de decaimiento (γ). Definición: el ritmo con que la atención cae con la distancia (
A(d)∝d^−γ). En el transformer: decide cuánta atención hay lejos y, por tanto, cuánto del KV se puede tirar sin perder masa. - Ventana D_f (nuestra). Definición: el número de tokens cercanos que basta conservar para capturar una fracción \((1-\varepsilon)\) de la atención, calculado en forma cerrada a partir de γ. En el transformer: un presupuesto de KV predictivo y sin parámetros, derivado de un γ medido una vez.
- Tolerancia ε. Definición: la pequeña fracción de masa de atención que aceptamos perder al recortar. En el transformer: es el mando que fija el tamaño de D_f —menor ε, ventana mayor—.
- Fase A / Fase B (γ<1 / γ>1). Definición: los dos regímenes que separa γ=1; con γ>1 la suma \(\sum d^{-\gamma}\) converge (cola ligera), con γ<1 diverge (cola pesada). En el transformer: marcan si un modelo es comprimible (ventana finita basta) o no (la masa está repartida por todo el contexto).
- Métodos heurísticos vs. principiados. Definición: los primeros eligen el presupuesto por posición o masa observada (StreamingLLM, H2O, SnapKV); los segundos por una cota de pérdida (Ada-KV, LAVa). En el transformer: es el campo con el que se compara D_f; ninguno deriva el presupuesto de un exponente de decaimiento.
- Masa ≠ fidelidad. Definición: capturar la masa de atención no garantiza preservar la salida, porque un token de poca masa puede pesar por la norma de su valor. En el transformer: es el límite honesto de D_f —razona sobre masa, necesaria pero no suficiente—.
Con el vocabulario fijado, vamos al problema y a la matemática de D_f.
21.3 El problema
En generación, el KV-cache guarda K y V de cada token pasado × cada capa × cada cabeza: crece linealmente con el contexto y, en contexto largo, es la memoria —no el cómputo— lo que ahoga. Comprimir = decidir qué K/V conservar y cuáles descartar (o fusionar, o cuantizar).
21.4 Lo que hace el campo
| Método | Qué conserva | Base | Ref |
|---|---|---|---|
| StreamingLLM | sumideros + ventana reciente | heurística (posición) | (Xiao et al. 2024) |
| H2O | “heavy hitters” + recientes | heurística (masa observada) | (Zhang et al. 2023) |
| Scissorhands | alta atención acumulada | heurística (masa) | (Liu et al. 2023) |
| FastGen | política adaptativa por cabeza | heurística + perfilado | (Ge et al. 2023) |
| SnapKV | lo importante para el final del prompt | heurística (atención del prompt) | (Li et al. 2024) |
| PyramidKV | más presupuesto en capas bajas | heurística (esquema por capa) | (Cai et al. 2024) |
| Ada-KV | presupuesto por cabeza | principiada (cota de pérdida) | (Feng et al. 2025) |
| LAVa | presupuesto cabeza+capa | principiada (pérdida de info) | (Shen et al. 2025) |
| KIVI | todos, a 2 bits | cuantización (eje ortogonal) | (Liu et al. 2024) |
Fíjate en la columna “Base”: todos eligen el presupuesto a partir de la posición, de la masa de atención observada, o de una cota de pérdida —ninguno lo deriva de un exponente de decaimiento—.
21.5 Nuestro D_f: la ventana derivada de γ
Aquí está la aportación, y la matemática es bonita y sencilla. Si la atención decae como A(d)∝d^−γ, conservar los D tokens más cercanos captura una fracción de la masa igual a \(\sum_{d=1}^{D} d^{-\gamma}\) dividido por el total. ¿Qué pasa al crecer D?
- γ > 1 (Fase B, cola ligera): la suma converge; la cola más allá de D se encoge como \(D^{1-\gamma}\). Una ventana finita \(D_f \sim \varepsilon^{-1/(\gamma-1)}\) captura una fracción \((1-\varepsilon)\) de la atención —donde ε es la pequeña fracción de masa que aceptamos perder (la tolerancia): cuanto menor ε, mayor la ventana \(D_f\)— → muy comprimible.
- γ = 1: la suma diverge como \(\log D\) → caso frontera.
- γ < 1 (Fase A, cola pesada): diverge como \(D^{1-\gamma}\) → la masa está repartida por toda la distancia; ninguna ventana finita la captura → difícil de comprimir.
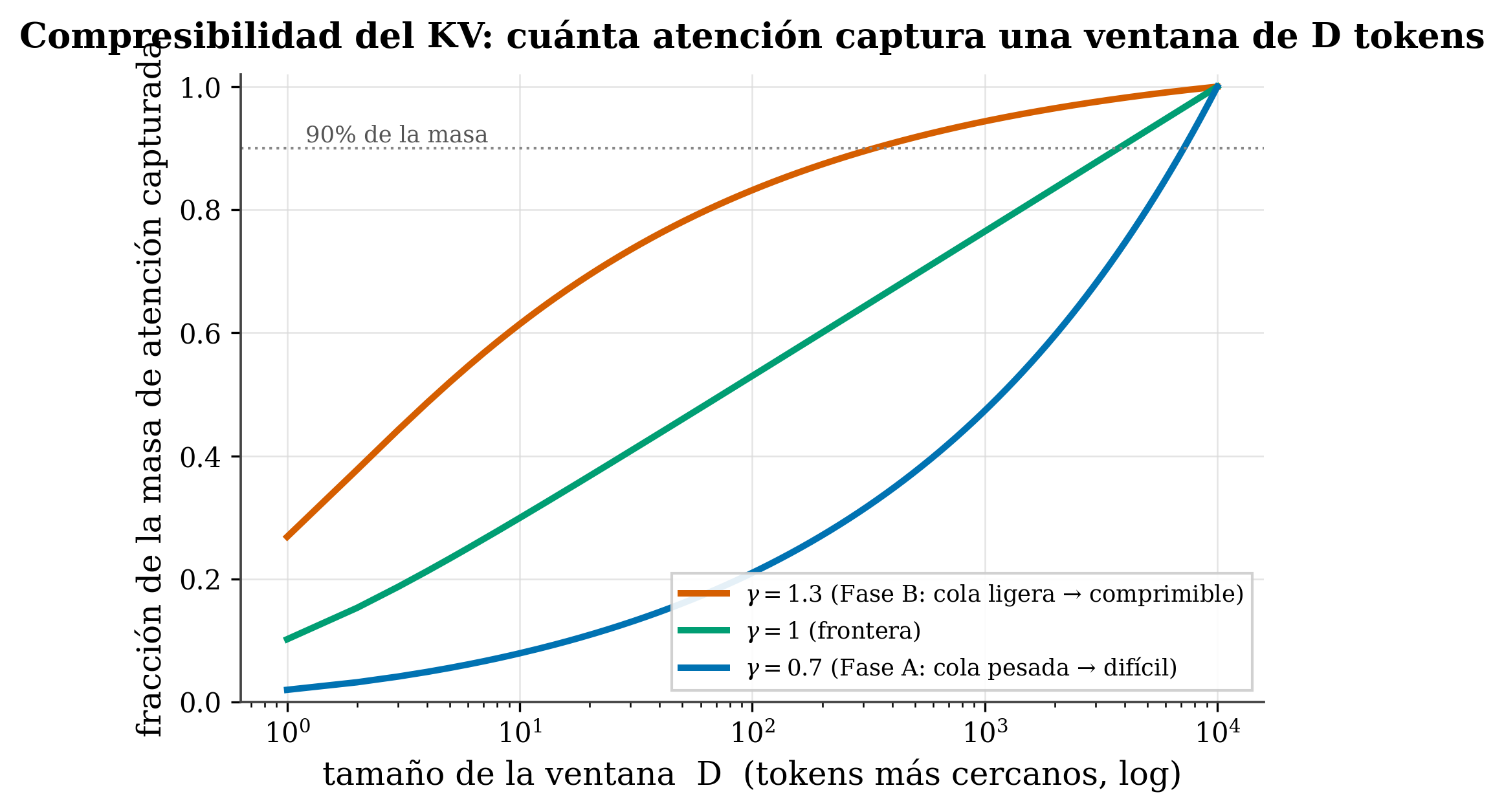
Por eso γ=1 separa dos regímenes de compresibilidad (es el resultado Q3 del Paper I (Marín 2026)), y la ventana D_f sale en forma cerrada del propio γ —medido una vez, sin parámetros que tunear—. Esa es la diferencia con el campo:
El hueco que llenamos: ningún método deriva el presupuesto de KV de un exponente de decaimiento. Todos usan masa observada, heurísticas o cotas. Nuestra novedad no es “comprimir el KV” (eso ya se hace mucho), sino el mecanismo: un presupuesto predictivo y sin parámetros a partir de un γ medido.
21.6 Honestidad — lo que falta validar
- Falta el cara a cara. Hay que comparar D_f contra los métodos principiados (Ada-KV, LAVa) a memoria igualada en benchmarks de tarea (RULER, LongBench, NIAH), no solo contra heurísticas. Ese benchmark head-to-head está pendiente: presentamos D_f como derivado y predictivo, no como demostrado superior.
- Captar masa de atención ≠ fidelidad de salida. Un token de poca masa puede importar por la norma de su valor (la crítica de Ada-KV). D_f razona sobre la masa, que es necesaria pero no suficiente.
- D_f va ENCIMA del sumidero y lo reciente, no los reemplaza: la atención real es cola-γ + sumidero + recencia (Cap. 17). El presupuesto total = sumidero + ventana local + D_f.
- Mide la tarea, no la perplejidad. La perplejidad puede seguir baja mientras la recuperación (needle) ya colapsó —la perplejidad la dominan los tokens locales que igualmente conservas—.
- D_f asume una cola de un solo exponente limpio; es más flojo en cabezas de inducción/recuperación con atención plana o multimodal.
tafagent incluye la receta X-19 (KV compression), que según el γ de tu modelo recomienda soft-decay / cutoff / literatura, y te calcula la memoria de KV a la longitud objetivo. Es D_f convertido en consejo práctico.
21.7 Resumen
- El KV-cache crece O(n) → cuello de botella; comprimir = qué K/V conservar.
- El campo elige el presupuesto por posición/masa observada/cotas (StreamingLLM, H2O, SnapKV, Ada-KV, LAVa…); ninguno lo deriva de un exponente de decaimiento.
- Nuestro D_f: como
A(d)∝d^−γ, una ventana finita captura \((1-\varepsilon)\) de la masa si γ>1 (comprimible), no si γ<1; γ=1 es la frontera y D_f sale en forma cerrada de γ (sin parámetros). - Honesto: el cara a cara con Ada-KV/LAVa está pendiente; masa ≠ fidelidad; D_f va encima de sumidero+recencia; mide tarea, no perplejidad.
Fin de la Parte II. Has visto nuestro territorio completo: leer mapas → aliasing → la ley γ → el atlas → sumideros → taxonomía → contexto largo → KV. Siguiente (Parte III): una lente más especulativa pero reveladora — la física de la atención (fases, termodinámica, transporte fraccionario, grokking).
21.8 Ejercicios
- Compresibilidad. Mirando la figura: ¿qué modelo comprimes mejor su KV, uno con γ=1,3 o uno con γ=0,7? ¿Por qué?
- La frontera. ¿Por qué γ=1 separa “comprimible” de “difícil”? (Piensa en si \(\sum d^{-\gamma}\) converge.)
- Honestidad. ¿Por qué no afirmamos que D_f sea mejor que Ada-KV? ¿Qué experimento faltaría?
- Masa ≠ fidelidad. Da un caso en el que un token con poca atención aún sea importante para la salida.